Following on from searching for books by the colour of the cover, it would be just plain rude if I didn’t have a stab at ripping off retrievr at the same time!
Once Iman gets back, I’m going to grill him mercilessly about the best way to analyse and match images. In the meantime, here’s my first stab at searching…
Using ImageMagick, I resized the book covers to 8×8 pixels and then stored the hex colour value of each of the 64 pixels in a database table.
For example, Nielsen’s “Designing Web Usability” changes from…

…to something like this (I’ve added the black lines)…

You can then give it an image like this one to search for…

…then cross your fingers and see what pops out the other end…
The search works by comparing the hex colours of the 8×8 version of the search image with the corresponding pixels of the book covers. Each book cover then gets ranked by how well it matches the search image.
The only catch is that it currently takes about over 30 seconds to complete the search, hence the need to get Iman on the case.
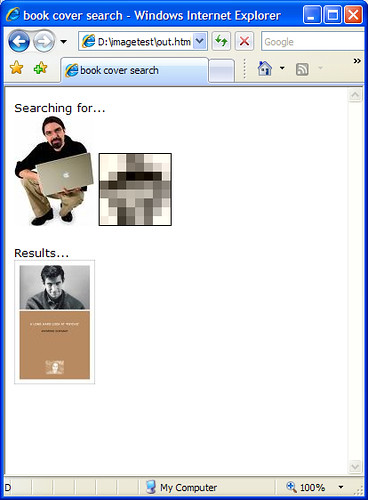
Anyway, I’m sure what you really want to know is what the lowdown on Michael Stephens is — here’s what came out the other end when I gave it a well known image of Mr Stephens…
Just for fun, here’s a few more searches…


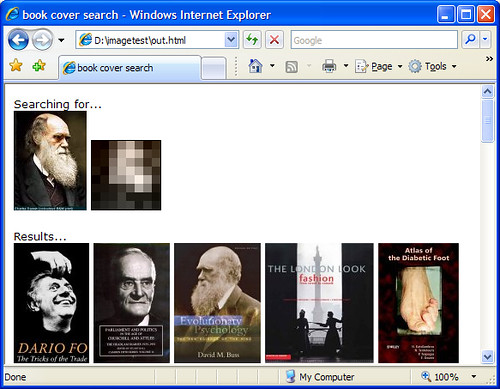
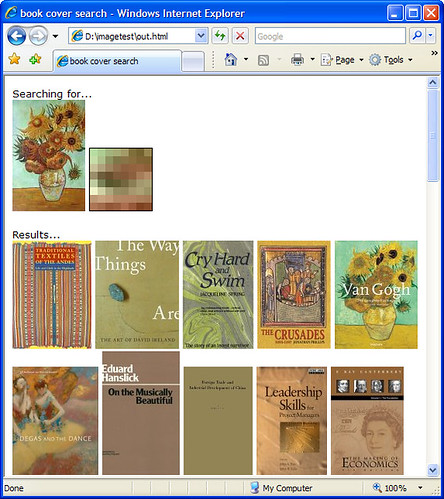
11 thoughts on “Michael Stephens = Norman Bates?!?”
Comments are closed.
I don’t know why, but I LOVE this.
Damn! What would happen if you made the image 16×16 px? Would you get more hits, or more accurate hits? (it’s pretty impressive at 8×8!)
c.
I was wondering the same thing too Carlos!


I’ve started reindexing the book covers using a 16×16 image, although I know it will make the search run considerably slower.
It should definitely improve the matching — here’s how Mr Stephens looks at 8×8 and 16×16:
The 16×16 is almost recognisable… kind of like looking at Michael through the bottom of a Coke bottle whilst squinting hard!
(heh — wouldn’t it be cool if, when Michael gave his next presentation, it was to a room full of librarians looking at him through Coke bottles whilst squinting!)
Dave, I WANT THIS! Do you think we can get them to build it into the functionality of 8.x? — q
Hi Susan!
I did mean to add an update to this post…
Moving to 16×16 seemed to make the matching worse, as the likelihood of a book cover matching the original image decreased — so, using 8×8 actually made for better matches!
There must be an optimum size that has just the right about of “vagueness” to give good matches, so I’ll keep on experimenting.
In terms of adding this into the OPAC, I did think it would be possible to analyse the book covers to get the average colour and then maybe that could be added to the MARC record (so it could become a searchable index)?
If you didn’t want hex colour codes in the MARC reccord, you could map the colour to the nearest web colour name. That way, you’d be able to run a keyword search and then limit the results to just “lightsalmon” coloured books 😀
Now that is most definitely the coolest thing I’ve seen in a long time.
The match for Beginning Perl is brilliant – have you considered jacking in this web stuff in favour of a career as an MS Paintbrush artist? 🙂
Hi, are you still working on the code?
This is really impressive. Was it made with what? perl?
Have you tried to apply this search to other things than book covers only? Like faces, animals, etc…
I was planning, some days ago, to make an app to search images through the web by an example image and thinking of do this using neural nets, but never go on coding… But your app could, maybe, does it much better.
Please, contact me.
Hello,
This is really cool. Great job. Don’t stop with this.
Regards,
Eneas