To go with Ned’s “Great Library Stereotypometer“, which seems to be lacking one vital item, here’s a handy Venn Diagram…
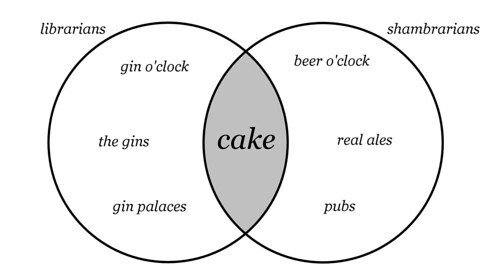
You may find it useful to copy the diagram out onto a small piece of card and keep about your person for reference purposes.
If you are a librarian and you meet a shambrarian:
- DO ask questions such as “would you like some more cake?” and “what is your favourite cake anecdote?”
- DO feel free to compliment the shambrarian if they are wearing a particularly witty t-shirt
- DO NOT bore the shambrarian by talking about your recent holiday tour of “Ye Olde Gin Palaces of London Town” or by reciting verbatim your top 50 gin based cocktail recipes
- DO NOT attempt to sexually arouse the shambrarian by showing them photographs of library porn (e.g. this, this, this or this)
- UNDER NO CIRCUMSTANCES should you say “if all the librarians got together, we could easily index the entire web… probably using an index card based system”
If you are a shambrarian and you meet a librarian:
- DO ask them questions such as “where is your closed stack1?” and “what is the Dewey classification for Chocolate Guinness Cake?”
- DO feel free to compliment the librarian if you think that they have particularly nice cupcakes
- DO NOT bore the librarian by showing them your Roy Tennant Fan Club membership card
- DO NOT embarrass the librarian by asking them if “colon classification” means what you think it means
- DO NOT attempt to sexually arouse the librarian by showing them photographs of shambrarian porn (e.g. this, this, this or this)
- UNDER NO CIRCUMSTANCES should you say “Google Scholar is much better than that *very* expensive product your library just bought”
1 The “closed stack” is where librarians store their cakes and usually has a “NO ENTRY — LIBRARIANS ONLY” sign on the door. If the librarian does not have enough room in their office, the closed stack may also be used to house the library’s gin distillery.

