After the success of the first event, held at Sheffield Hallam University last July, we’re pleased to announce that Manchester Metropolitan University Library Services have kindly offered to host the next UK Information Literacy & Summon Day on Thursday July 25th.
Put the date in your diary and keep an eye on the event blog!
http://summonil2013.wordpress.com/
The venue is easy to get to from Manchester Airport 🙂
Category: Library Stuff
Dumping the OPAC #2 – Usage Data
File this under “things I wished I’d started doing a long time ago”, but we began collecting usage data from Summon a few months back, using a modified version of Matthew Reidsma’s Summon-Stats script. In that time, we’ve built up a log of just over 310,000 user transactions from Summon searches for around 160,000 distinct items[1].
It’s early days yet and we’d need to collate more data before we could launch this as a truly viable service, but we’ve got enough usage data to start driving “people who clicked on this item, also clicked on these…” style suggestions (based on the same methodology we’ve been using since late 2005 on our OPAC):
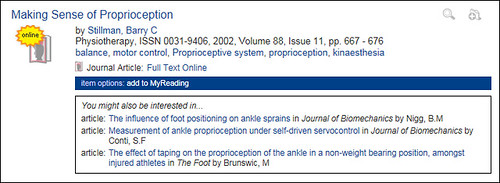
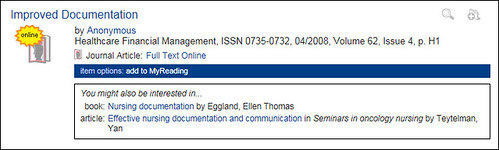


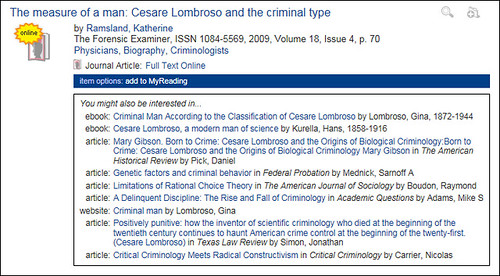




Although the suggestions seem to mostly be relevant and on-topic even at this this early stage, given more usage data, they’d become increasingly refined and improved.
I guess conceptually this is similar to the Ex Libris bX service, but it also exposes items that wouldn’t necessarily be tracked via link resolver logs (e.g. books, web sites, off-air TV recordings, items in the repository, etc).
[1] – that represents just 0.12% of the items in our Summon instance
Dumping the OPAC #1 – The Project Spec
To go into a little more detail about what we’re hoping to achieve, here’s the project spec. Primarily, we’ll be creating a new library portal (currently dubbed “MyLibrary”) that will provide a bespoke view of key library services and will include the following planned functionality:
- the ability to view items on loan and renew them, and see details of current holds/requests and their status
- allow users to place hold requests from within Summon
- within Summon search results, highlight which items the user has previous borrowed
- provide easy access to module reading lists
- provide the user with a history of items they’ve borrowed previously from the library
- links to the relevant LibGuides for the user
- a feed of new items (books, journals, journal articles, etc) tailored to the modules that the student is studying, based on analysis of circulation and e-resource activity
- offer an opt-in service that will track usage within Summon and the link resolver, so that the user can re-run previous searches and locate articles that they’ve viewed
- generate bespoke “you might be interested in…” suggestions based on the user’s recent borrowing
- extend the functionality of the reading list software to allow students to create their own lists of items found in Summon
The new library portal will replace the existing library page within Blackboard (which is currently a static page of links) and will integrate with the student portal to provide an overview of the user’s library account.
Development work started about 2 weeks ago and the aim is to launch the initial version of the portal (with the functionality marked in bold) by mid-June. The remaining functionality will be gradually iterated into the library portal during the 2013/14 academic year.
Operation Dump the OPAC
If you follow me on Twitter (@daveyp), you’ll probably know already that we’re about to take the plunge and retire our OPAC in favour of using Summon. There are a few drivers behind this, including:
- the OPAC’s search facility is crude by modern standards and it’s difficult to refine a search
- it looks like the OPAC can’t display RDA records correctly, but Summon can
- we’re planning to replace the ILS/LMS within the next couple of years and, chances are, whatever we get to replace it won’t have an OPAC
- getting rid of the OPAC means one less thing we have to show students how to use
This isn’t going to be a trivial project, as we need to integrate the missing circulation functionality (holds, renewals, etc) into Summon and our version of Horizon has no web services, but it’s definitely “doable”.
As I’ve blogged about previously, the Summon interface can be easily tweaked if you’re familiar with jQuery, so there’s a lot of potential for integrating the circulation functionality in a way that will appear seamless to the end users.
As the project progresses, I’ll blog and post snippets of code that might be useful for other libraries. In the meantime, you can see some screenshots of the work-in-progress on Flickr:
http://www.flickr.com/photos/davepattern/sets/72157633427926980/
The Magic Microphone and the Horrible Headphones
A while back, I had a daft idea to try and use all of the library circulation and graduate attainment data to pinpoint which books were the ones most likely to be borrowed by high achieving students, as I thought it might be fun to highlight those on the OPAC — after all, if you had the choice of two books on a topic, why not go for the one that the brightest students had borrowed the most?
Anyway, I came up with a formula to calculate a percentage score for each item, based on the attainment of the students who borrowed it and the overall distribution of all graduates, where 100% meant that only students who achieve a first class honours degree borrowed the item. I then discarded items borrowed by less than 100 students and held my breath to see which scholarly tome achieve the highest score. What I hadn’t expected to discover was that we appear to have some magic microphones, capable of bestowing high marks to all who borrow them…
Quite why these Shure SM58 microphones seem to mostly be borrowed by students who gain the best honours degrees, I can’t say!
On the other hand, the item with the lowest score turned out to be a set of headphones, borrowed mostly by students who achieved a 2:2 or a third…
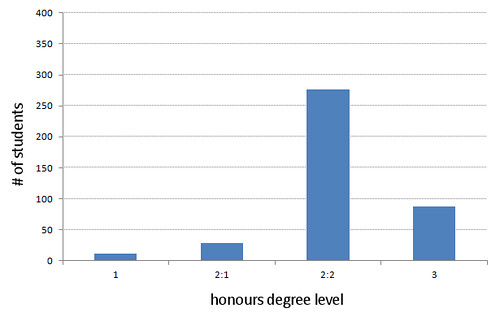
The more superstitious amongst you will be glad to hear that the headphones have since been weeded … and, for all I know, buried in an unmarked grave at midnight 😀
For those of you who are interested in such things, here are the books that scored highest:
- Neuroanatomy : an illustrated colour text (80.08%)
- Audio-vision : sound on screen (78.73%)
- The foundations of social research (78.40%)
- The computer music tutorial (78.38%)
- Critical discourse analysis : the critical study of language (78.24%)
- Understanding the self (78.09%)
- Doing qualitative research : a practical handbook (78.01%)
- Personality : theory and research (77.99%)
- Cognitive psychology and its implications (77.64%)
- A way of being (77.32%)
Curiously, almost all of the lowest scoring books are business or law titles.
Please give generously…
The Boolean Sanctuary is a UK charity run by librarians, working to protect neglected & homeless Boolean Operators. Please give generously.
— Dave Pattern (@daveyp) April 28, 2012
… The Boolean Sanctuary will never put a healthy Boolean Operator to sleep. If you would like to adopt AND, NOT and/or OR, please call us.
— Dave Pattern (@daveyp) April 28, 2012
… please note that the Boolean Sanctuary is not affiliated with the Royal Society for the Prevention of Cruelty to Venn Diagrams
— Dave Pattern (@daveyp) April 28, 2012
“Library search tools. Could we make them harder to use?”
Everyone now and then you come across a blog post that really resonsates and this is one: “Library search tools. Could we make them harder to use?” by @carolgauld.
I was being cheeky when I proposed Dave’s Law, but this is something that we seriously need to get a grip on…
My daughter now thinks, perhaps rightly, that the library search tools are complicated, old fashioned and very hard to use. She will most certainly be avoiding using them and I would think this would mean she will avoid using the library and will stick with Google Scholar which she feels comfortable using without training. Let me just reiterate here: week one of a degree which will take six years part time to do and the compulsory library instruction class, which threw the hardest and least useful content up first, completely alienated the student. She sees the library and it’s search tools as a last resort now and it will be incredibly difficult to change her mind.
…this strikes to the heart of the issue — we collectively claim to be a service that connects our users to information, yet we seem to go out of our way to achieve the exact opposite.
Students who don’t use the library, or who are put off using our resourses, are at a clear disadvantage — they’re statistically more likely to achieve lower grades and, if the preliminary findings from LIDP Phase 2 prove to be correct, nearly 9 times more likely to drop out of their studies.
Most students don’t need to know “Venn diagram explaining Boolean searching, phrase searching, truncation and substitution, nesting and mathematical operators” — and they especially don’t need that ramming down their throats as part of a library induction session.
Libraries should be at the cutting edge of search, but we’re still stuck in the Boolean Age. We’re obsessed with the options on the “advanced search” page and not with the user experience. We think it’s more important to have a MARC view option in the OPAC than for the catalogue search results to be relevancy ranked.
This is 2012 not 1980. We can design our communications to be friendly and welcoming so they suit our users just like Facebook and Amazon do. If we can make our search tools easy to use without instruction students will have a go and then hopefully get help if they get stuck. We can let go of the outdated notion that everyone who enrols at university needs to develop searching skills based on arcane library-only metadata standards. They will never need to use Dialog on a dial up modem so constructing complicated nested queries is pointless! If we try to give them just enough instruction at just the time they need it there is a far greater chance they will retain that knowledge and use it again.
Let’s start changing the way we do things before we become obselete and totally irrelvant to our users. Vive la Révolution Bibliothèque!
A week on Summon (revisited)
After yesterday’s blog post, I thought I’d have a go at narrowing down my definition of a “separate search”.
If a user enters some search terms, and then uses 2 facets to refine the search before clicking on a result, I was classing that as 3 separate searches — what niggled me overnight was that that approach might inflate the facet use statistics …after all, 30.6% of all searches used at least one facet felt a little high given that I’m forever hearing staff moan that students never use the facets, no?!
For today’s blog post, I’ve removed all searches that didn’t lead to a result click. (There’s a small caveat that my jQuery code currently doesn’t capture a result click for links to the OPAC where the user clicked on the availability message (highlighted in red below) — this is because my jQuery code that captures the result clicks runs once the page has loaded, but before the AJAX’d availability information has been retrieved. When I get some time, I’ll see if I can find a way around that.)
So, let’s see how much of a difference that makes to yesterday’s stats…
- 29.4% of searches used at least one facet to refine the results
- 10.4% of searches were refined using the content type facet (e.g. newspaper articles, book reviews, books/ebooks, journal articles, etc)
- 7.8% of searches were refined to just items with full text available online
- 9.4% of searches were refined by publication date
- 5.6% of searches were refined to just articles from scholarly publications (including peer-review)
- 3.7% of searches were refined using the language facets
- 2.5% of searches were refined using the subject term facets
- 2.1% of searches used a Boolean operator, with nearly all of them being AND
So, that overall figure for the % of searches which used at least one facet hasn’t dropped by much from yesterday’s figure of 30.6%.
Anyone who follows me on Twitter will know that I like to cheekily mock the importance of Boolean and the data from the last 7 days reveals a few things:
- no-one who used a Boolean NOT in their search clicked on a result
- only 0.07% of searches (that’s just 7 searches in every 10,000!) used a Boolean OR, which is arguably the most useful operator to use
- unless you’re using a search that includes one of the other Boolean operators, the use of AND is pretty much redundant as it’s the default Boolean operator in a search (i.e. the search “dogs AND cats” is the same as “dogs cats”)… so why are we telling students to use it in Summon?
After poking a bit of fun at someone for entering a 356 word search query yesterday, I can reveal that the longest search in the last 7 days that resulted in a result click was 98 words (it was a paragraph copied and pasted from a journal article).
I guess the big question here is why the disconnect between the “students don’t use facets” mantra and the actual usage data?
Finally, I thought I’d figure out how many results are clicked on after a search…
A week on Summon
[ update: slightly revised stats are available here! ]
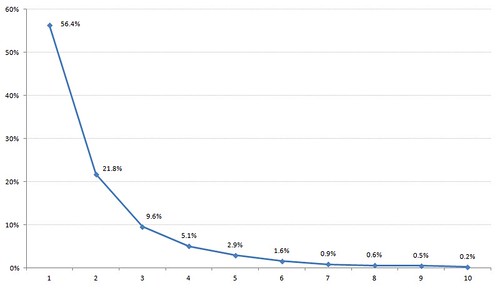
We’ve just started collecting in-depth data about how students are searching Summon (keywords entered, facets selected, etc) and I thought some of you might be interested in an early analysis from the last 7 days (just under 40,000 separate searches by 2,807 students)…
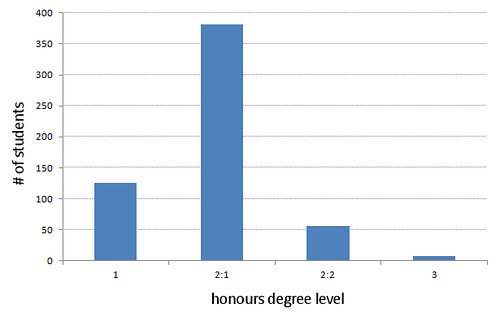
- On average, students used 4.5 keywords per search (the mode is 3 keywords and the majority of searches used 3 keywords or less — view graph) [1]
- 30.6% of searches used at least one facet to refine the results [2]
- 11.7% of searches were refined using the content type facet (e.g. newspaper articles, book reviews, books/ebooks, journal articles, etc)
- 9.5% of searches were refined to just items with full text available online
- 9.2% of searches were refined by publication date [3]
- 7.2% of searches were refined to just articles from scholarly publications (including peer-review)
- 3.4% of searches were refined using the language facets [4]
- 2.6% of searches were refined using the subject term factes
- 2.3% of searches used a Boolean operator, with AND being by far the most common (2.23% of searches) [5]
notes:
[1] – One student copied & pasted the following 356 word title & abstract into the search box!
Peter J. Shaw, David J. Rawlins Article first published online 2 AUG 2011 DOI:10.1111/j.1365-2818.1991.tb03168.x 1991 Blackwell Science Ltd Issue Journal of Microscopy Volume 163, Issue 2, pages 151–165, August 1991 Additional Information(Show All) How to CiteAuthor InformationPublication History SEARCH Search Scope Search String Advanced >Saved Searches > ARTICLE TOOLS Get PDF (1119K) Save to My Profile E-mail Link to this Article Export Citation for this Article Get Citation Alerts Request Permissions Share Abstract References Cited By Get PDF (1119K) Keywords Confocal microscopy;three-dimensional fluorescence microscopy;point-spread function;deconvolution;computer image processing SUMMARY We have measured the point-spread function (PSF) for an MRC-500 confocal scanning laser microscope using subresolution fluorescent beads. PSFs were measured for two lenses of high numerical aperture—the Zeiss plan-neofluar 63 × water immersion and Leitz plan-apo 63 × oil immersion—at three different sizes of the confocal detector aperture. The measured PSFs are fairly symmetrical, both radially and axially. In particular there is considerably less axial asymmetry than has been demonstrated in measurements of conventional (non-confocal) PSFs. Measurements of the peak width at half-maximum peak height for the minimum detector aperture gave approximately 0·23 and 0·8 μm for the radial and axial resolution respectively (4·6 and 15·9 in dimensionless optical units). This increased to 0·38 and 1·5 μm (7·5 and 29·8 in dimensionless units) for the largest detector aperture examined. The resulting optical transfer functions (OTFs) were used in an iterative, constrained deconvolution procedure to process three-dimensional confocal data sets from a biological specimen—pea root cells labelled in situ with a fluorescent probe to ribosomal genes. The deconvolution significantly improved the clarity and contrast of the data. Furthermore, the loss in resolution produced by increasing the size of the detector aperture could be restored by the deconvolution procedure. Therefore for many biological specimens which are only weakly fluorescent it may be preferable to open the detector aperture to increase the strength of the detected signal, and thus the signal-to-noise ratio, and then to restore the resolution by deconvolution. Get PDF (1119K) More content like thisFind more content like this article Find more content written by Peter J. ShawDavid J. RawlinsAll Authors ABOUT USHELPCONTACT USA
…sadly, Summon failed to find a result for that as we don’t subscribe to the article!
[2] – Normally, you search Summon by entering your keywords then, after the results appear, you select facets to refine your search and each facet selection invokes a new search. So, if you ran a search and then select 2 facets, that will be logged as 3 separate searches (1 without any facets, and 2 with).
[3] – Mostly, the publication date facet is being used to limit the search to the X most recent years.
[4] – The vast majority of the content in our Summon instance is in English and, apart from one search that refined the results to just Italian, every use of the language facet was to refine the results to English only.
[5] – Boolean operators have to be entered in UPPER CASE in Summon, with an invisible AND being implict in any multi keyword search that doesn’t include Boolean. Looking at the searches queries that included a Boolean operator, 6% were entered entirely in upper case, implying that the user wasn’t conciously invoking a Boolean search.
Dave’s Law
I’d love to have a law named after me, so here goes:
Dave’s Law
users should not have to become mini-librarians in order to use the library
If you ever find yourself needing to invoke Dave’s Law, please let me know 🙂