After yesterday’s blog post, I thought I’d have a go at narrowing down my definition of a “separate search”.
If a user enters some search terms, and then uses 2 facets to refine the search before clicking on a result, I was classing that as 3 separate searches — what niggled me overnight was that that approach might inflate the facet use statistics …after all, 30.6% of all searches used at least one facet felt a little high given that I’m forever hearing staff moan that students never use the facets, no?!
For today’s blog post, I’ve removed all searches that didn’t lead to a result click. (There’s a small caveat that my jQuery code currently doesn’t capture a result click for links to the OPAC where the user clicked on the availability message (highlighted in red below) — this is because my jQuery code that captures the result clicks runs once the page has loaded, but before the AJAX’d availability information has been retrieved. When I get some time, I’ll see if I can find a way around that.)
So, let’s see how much of a difference that makes to yesterday’s stats…
- 29.4% of searches used at least one facet to refine the results
- 10.4% of searches were refined using the content type facet (e.g. newspaper articles, book reviews, books/ebooks, journal articles, etc)
- 7.8% of searches were refined to just items with full text available online
- 9.4% of searches were refined by publication date
- 5.6% of searches were refined to just articles from scholarly publications (including peer-review)
- 3.7% of searches were refined using the language facets
- 2.5% of searches were refined using the subject term facets
- 2.1% of searches used a Boolean operator, with nearly all of them being AND
So, that overall figure for the % of searches which used at least one facet hasn’t dropped by much from yesterday’s figure of 30.6%.
Anyone who follows me on Twitter will know that I like to cheekily mock the importance of Boolean and the data from the last 7 days reveals a few things:
- no-one who used a Boolean NOT in their search clicked on a result
- only 0.07% of searches (that’s just 7 searches in every 10,000!) used a Boolean OR, which is arguably the most useful operator to use
- unless you’re using a search that includes one of the other Boolean operators, the use of AND is pretty much redundant as it’s the default Boolean operator in a search (i.e. the search “dogs AND cats” is the same as “dogs cats”)… so why are we telling students to use it in Summon?
After poking a bit of fun at someone for entering a 356 word search query yesterday, I can reveal that the longest search in the last 7 days that resulted in a result click was 98 words (it was a paragraph copied and pasted from a journal article).
I guess the big question here is why the disconnect between the “students don’t use facets” mantra and the actual usage data?
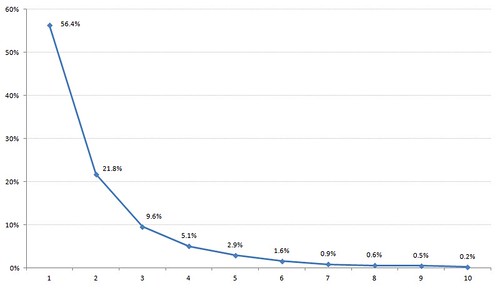
Finally, I thought I’d figure out how many results are clicked on after a search…



{kind=link}