Many thanks to those of you who’ve tested the code from yesterday! Those of you outside of the UK might want to see if this version works slightly faster for you:
hippie_spellcheck_v0.02.txt
The next thing I’ll be looking at is how to optimise the spellchecker dictionary for each library. Some of you will already have read this in the email I sent out this morning or in the comment I left previously, but I’m thinking of attacking it this way:
1) Start off with a standard word list (e.g. the 1000 most commonly used English words) to create the spellcheck dictionary for your library, as the vast majority should match something on your catalogue.
2) Add some extra code to your HIP so that all successful keyword searches get logged. Those keywords can then be added to your dictionary.
It could even be that starting with an empty dictionary might prove to be more effective (i.e. don’t bother with step 1) — just let the “network effect” of your users searching your OPAC generate the dictionary from scratch (how “2.0” is that?!)
To avoid any privacy issues, the code for capturing the successful keywords could be hosted locally on your own web server (I should be able to knock up suitable Perl and PHP scripts for you to use). Then, periodically, you’d upload your keyword list to HIPpie so that it can add the words to your spellchecker dictionary.
What about if you don’t have SirsiDynix HIP? Well, as mentioned previously, the spellchecker has been implemented as a web service (more info here), and the HIP spellchecker makes use of that web service to get a suggestion. At the moment it only returns text or XML, but I’m planning to add JSON as an option soon. Also, if you have a look at the HIP stylesheet changes, you can see the general flow of the code:
1) insert a div with an id of “hippie_spellchecker” into the HTML
2) make a call to “https://library.hud.ac.uk/hippie_perl/spellchecker2.pl” with your library ID (currently “demo”) and the search term(s) as the parameters
3) the call to “spellchecker2.pl” returns JavaScript to update the div from step 1
4) clicking on the spelling suggestion triggers the “hippie_search” JavaScript function which is responsible for creating a search URL suitable for the OPAC (which might include things like a session ID or an index to search)
None of the above 4 steps are specifically tied to the SirsiDynix HIP and should be transferable to other OPACs. I’ve put together a small sample HTML page that does nothing apart from pull in a suggestion using those 4 steps:
example001.html
If you do want to have a go with your own OPAC, please let me know — at some point I’ll need people to register their libraries so that each can have their own dictionary, and I might start limiting the number of requests that any single IP address can make using the “demo” account. Also, it would be good to build up a collection of working implementations for different OPACs.
Tag: spellchecker
Spellchecker + Network Effect = Better Spellchecker?
I’ve been having a few email discussions relating to whether or not it’s best to use a standard dictionary of words for an OPAC spellchecker or an index created from the actual holdings of that library…
Standard dictionary
pros: correct spelling
cons: suggestion might not find any results, might not contain buzz/new words
Custom dictionary
pros: suggestions should find results
cons: will contain mis-spellings (e.g. “mangement”), needs regular updates, might be difficult to extract the words from ILS/LMS/OPAC
I’m beginning to think that the best of both worlds might be to start with a standard dictionary and then let your users/patrons build upon that. In other words, whenever someone carries out a successful keyword search on the OPAC, automatically add the keyword(s) they used to your dictionary so that they can appear as spelling suggestions in the future.
Any comments?
HIPpie “Did you mean?” ready for testing
I’ve just finished plugging the first bit of HIPpie into our test OPAC:
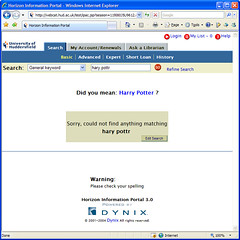
I’m gonna be out of the office for most of next week (3 days in London at Online Information 2007), but I’ll start contacting those of you who said you’d like to be involved with the testing. The test code just requires you to paste a short block of JavaScript into one of the HIP stylesheets (searchinput.xsl).
At present, the version I’ve plugged into our test OPAC uses a generic US word list, but the idea is to allow libraries to either upload their own word lists or choose from country specific ones.
Although the code needs to be able to create links that contain the HIP profile string and the session ID, neither of these are actually passed back to the server at Huddersfield (just in case session privacy is an issue).