Those who went to either Richard Wallis’ API session or my OPAC session at the UKSG 2009 Conference will have heard about Richard‘s Open Source Juice Project.
The project, which was launched at Code4Lib 2009, is designed to allow developers to create OPAC extensions (or, if you prefer, “bells and whistles”) that, in theory, should be product independent. This is such a genius idea!
Part of the problem with the stuff we’ve developed at Huddersfield is that we had to put an infrastructure in place around the OPAC in order to allow us to do the tweaking — an extra web server, MySQL databases, etc. It works well for us, but it’s not an easily transferable model. I’m always more than happy to share the “how we did it” but, more often than not, the actual code is too reliant on that back end infrastructure.
I need to do a bit more testing, but I’m hoping to have a HIP 3 “metadef” ready soon. The job of the metadef is to define whereabouts on the OPAC page things like the ISBN, author and title appear, and therefore will be different for every OPAC product. However, once you have a suitable metadef for your OPAC, you can start using the Juice extensions to add extra functionality — I had a quick play around last night just to prove that Juice will work with HIP 3…
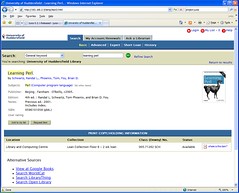
I’m not sure if this is in Richard’s plans for Juice, but it would be handy to extend the metadef to include other OPAC specific information — e.g. given an ISBN or some keywords, how do you construct a URL to trigger a search on that OPAC. That’d be really useful for embedding recommendations, etc.
Tag: hip
QR Codes in the OPAC?
Just wondering if anyone out there is already experimenting with QR Codes in their OPAC?
We’re trying to figure out the best way of providing item location information (e.g. floor and shelfmark), so I’m interested to know if anyone has already done this.
HIPpie — how to build a dictionary
Many thanks to those of you who’ve tested the code from yesterday! Those of you outside of the UK might want to see if this version works slightly faster for you:
hippie_spellcheck_v0.02.txt
The next thing I’ll be looking at is how to optimise the spellchecker dictionary for each library. Some of you will already have read this in the email I sent out this morning or in the comment I left previously, but I’m thinking of attacking it this way:
1) Start off with a standard word list (e.g. the 1000 most commonly used English words) to create the spellcheck dictionary for your library, as the vast majority should match something on your catalogue.
2) Add some extra code to your HIP so that all successful keyword searches get logged. Those keywords can then be added to your dictionary.
It could even be that starting with an empty dictionary might prove to be more effective (i.e. don’t bother with step 1) — just let the “network effect” of your users searching your OPAC generate the dictionary from scratch (how “2.0” is that?!)
To avoid any privacy issues, the code for capturing the successful keywords could be hosted locally on your own web server (I should be able to knock up suitable Perl and PHP scripts for you to use). Then, periodically, you’d upload your keyword list to HIPpie so that it can add the words to your spellchecker dictionary.
What about if you don’t have SirsiDynix HIP? Well, as mentioned previously, the spellchecker has been implemented as a web service (more info here), and the HIP spellchecker makes use of that web service to get a suggestion. At the moment it only returns text or XML, but I’m planning to add JSON as an option soon. Also, if you have a look at the HIP stylesheet changes, you can see the general flow of the code:
1) insert a div with an id of “hippie_spellchecker” into the HTML
2) make a call to “https://library.hud.ac.uk/hippie_perl/spellchecker2.pl” with your library ID (currently “demo”) and the search term(s) as the parameters
3) the call to “spellchecker2.pl” returns JavaScript to update the div from step 1
4) clicking on the spelling suggestion triggers the “hippie_search” JavaScript function which is responsible for creating a search URL suitable for the OPAC (which might include things like a session ID or an index to search)
None of the above 4 steps are specifically tied to the SirsiDynix HIP and should be transferable to other OPACs. I’ve put together a small sample HTML page that does nothing apart from pull in a suggestion using those 4 steps:
example001.html
If you do want to have a go with your own OPAC, please let me know — at some point I’ll need people to register their libraries so that each can have their own dictionary, and I might start limiting the number of requests that any single IP address can make using the “demo” account. Also, it would be good to build up a collection of working implementations for different OPACs.
Visual virtual shelf browsing
The Zoomii web site seems to be getting a lot of attention at the moment, so I got wondering how easy/difficult it would be do to a virtual bookshelf in the OPAC…

It’s definitely a “crappy prototype” at the moment, and the trickiest thing turned out to be getting the iframe to jump to the middle (where, hopefully, the book you’re currently browsing is shown). Anyway, you can see it in action on our OPAC.
I suspect the whole thing would work much better in Flash and it would look really cool if it used a Mac “dock” style effect. I wonder if I can persuade Iman to conjure up some Flash? 😉
HIPpie “Did you mean?” ready for testing
I’ve just finished plugging the first bit of HIPpie into our test OPAC:
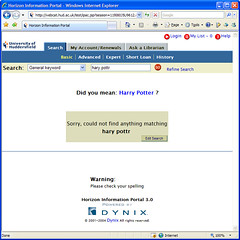
I’m gonna be out of the office for most of next week (3 days in London at Online Information 2007), but I’ll start contacting those of you who said you’d like to be involved with the testing. The test code just requires you to paste a short block of JavaScript into one of the HIP stylesheets (searchinput.xsl).
At present, the version I’ve plugged into our test OPAC uses a generic US word list, but the idea is to allow libraries to either upload their own word lists or choose from country specific ones.
Although the code needs to be able to create links that contain the HIP profile string and the session ID, neither of these are actually passed back to the server at Huddersfield (just in case session privacy is an issue).
HIP XML Parser (v0.01) – search parser
Okay folks – here’s the companion piece of code to the bib parser I posted a few weeks ago!
http://www.daveyp.com/files/stuff/xmlparser/search.pl
As with the previous code, this is alpha at best and should be treated as such. However, if you have any suggestions then please feed them back to me.
As well as specifying your own $url, you can also tweak the $maxResults value to determine just how many results you’ll actually get back. This will override the npp value in the URL — this means you should be able to lift a keyword search URL from HIP (which might just return sets of 10 or 20 at a time) and get the script to actually bring back as many results as you want (e.g. 100 or 1,000).
Continue reading “HIP XML Parser (v0.01) – search parser”
HIP XML Parser (v0.01)
This is some code that I’ve been meaning to make available for public consumption for weeks, but we’ve been up to our necks with our RFID tender at Huddersfield recently.
The basic idea is to convert the XML output of HIP 2 and HIP 3 into a Perl data structure, which you can then use to repurpose your bib data and searches for other uses (e.g. to provide an OpenSearch interface).
The first chunk of code I’m making available provides a function (parseBib) that will convert the XML from a full bib page into a data structure. Given the v0.01, you should treat this as alpha code at best!
http://www.daveyp.com/files/stuff/xmlparser/bib.pl
The above Perl script also contains some code to fetch the XML (using LWP) and will also dump (using Data::Dumper) the resulting Perl data structure to an output text file (dump_output.txt). I’ve also uploaded the code as a CGI file that you can run to display the Data::Dumper output – e.g.:
Building an object-oriented database system : the story of O2 /
Just to get you started, here’s some further info…
Continue reading “HIP XML Parser (v0.01)”
HIP Tip: changing the timeout
This is in response to an email Anne Barnard posted to the Horizon-L mailing list:
I have my global settings session timeout set to 5 minutes, and my search timeout set to 2 minutes. I’m starting to get complaints from remote users that they timeout to quickly. How long are other libraries making their settings? We’re a public library and people frequently walk away without logging out.
I didn’t see anyplace where this could be set for profiles rather than globally.
Assuming that your public OPACs have a specific range of IP addresses allocated to them (e.g. you’ve set them up on their own subnet), then it’s possible to tweak the expiretimer.xsl to only use the timeout for those machines:
…the bits you need to add are shown in red, and you’ll need to amend the IP address accordingly.
If you need to check for multiple IP addresses, then simply expand that if statement, e.g.:
if(ip.indexOf(" 10.2.8")>0 || ip.indexOf(" 10.2.9")>0)
…will only run the timeout for IP addresses starting with 10.2.8.* and 10.2.9.*
There’s probably quite a few ways of achieving the above, so please let me know if you’ve got a simpler method!
The usual notes apply:
- this worked fine with HIP 3.04 UK, but may not work with any other release
- make sure you back the file up before editing
- try it on a test HIP installation first
Live OPAC search terms display
Another shameless hack inspired by the “Making Visible the Invisible” at SPL.
I’ve tweaked HIP to cache keyword search terms and then put together a couple of pages that display successful searches (in tasteful shades of purple and lilac) and failed searches (in gruesome greens).
IE has a nice CSS blur, so I’ve coupled that with Ajax to provide a constantly updating web page where new terms appear at the front and then drop slowly to the back, becoming more and more blurred and darker as they recede (click to view full size versions):


Curse you Superpatron!
It’s way past my bedtime, but the Ann Arbor Superpatron has been planting ideas in my head again…
Recently Checked Out Books feed (in RSS or otherwise)
I’ve not built a feed, but I have come up with these two representations of the most recent check outs (click for larger versions):
1) The last 30 covers to walk out the door…

2) Word Splat!…

…that particular splat is entitled “And Treacle Challenge Yorkshire” and is now on sale for only $395,000 (serious bidders only please!)
Word Splat! is made up of words from the titles of the most recent X number of check outs (where X is a roughly a handful).
I made a typo when initially coding the Word Splat!, and ended up with a random sub selection of words at the top left. I kinda like that, so whatever you get at the top left (if anything) is officially the title of that Splat!
update…
I’ve added three more book collages:
1) 30 Overdue Books
2) 30 Most Recent Requests
3) 30 Most Borrowed Books
The “Overdue Books” are a random selection of items that were due back on the previous day, but have yet to turn up.