Those who went to either Richard Wallis’ API session or my OPAC session at the UKSG 2009 Conference will have heard about Richard‘s Open Source Juice Project.
The project, which was launched at Code4Lib 2009, is designed to allow developers to create OPAC extensions (or, if you prefer, “bells and whistles”) that, in theory, should be product independent. This is such a genius idea!
Part of the problem with the stuff we’ve developed at Huddersfield is that we had to put an infrastructure in place around the OPAC in order to allow us to do the tweaking — an extra web server, MySQL databases, etc. It works well for us, but it’s not an easily transferable model. I’m always more than happy to share the “how we did it” but, more often than not, the actual code is too reliant on that back end infrastructure.
I need to do a bit more testing, but I’m hoping to have a HIP 3 “metadef” ready soon. The job of the metadef is to define whereabouts on the OPAC page things like the ISBN, author and title appear, and therefore will be different for every OPAC product. However, once you have a suitable metadef for your OPAC, you can start using the Juice extensions to add extra functionality — I had a quick play around last night just to prove that Juice will work with HIP 3…
I’m not sure if this is in Richard’s plans for Juice, but it would be handy to extend the metadef to include other OPAC specific information — e.g. given an ISBN or some keywords, how do you construct a URL to trigger a search on that OPAC. That’d be really useful for embedding recommendations, etc.
Tag: opacs
QR Codes in the OPAC?
Just wondering if anyone out there is already experimenting with QR Codes in their OPAC?
We’re trying to figure out the best way of providing item location information (e.g. floor and shelfmark), so I’m interested to know if anyone has already done this.
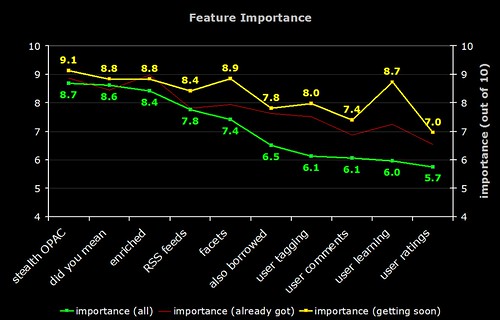
OPAC Survey 2009
Almost 2 years ago, 729 of you generously took time to fill out a survey about OPACs (archived here). You can find a selection of blog posts about the results here.
I’m pleased to say that a follow-up survey is now being conducted by Bowker and I’d encourage as many of you as possible to fill it in. For every 100 responses, Bowker will donate a gift of schoolbooks to deprived children via the Oxfam Unwrapped scheme 🙂

I think in 2007 we managed to gather enough statistical evidence to say “OPACs suck” and it’ll be interesting to see how much has changed in the last couple of years! Quite a few of you were hoping to implement new features in your OPACs …did it happen? …did those features meet your expectations?
JISC Developer Happiness Days (dev8D)
For my sins, I’m going to be facilitating the OPAC Community Meeting at the JISC Developer Happiness Days event in London next week.
Although we’ve got “OPAC” in the name, I think the session should include anything to do with library catalogues, library usage data, MARC records, federated search engines, revelancy ranking, facets, etc
We’d like to kick the session of with several “Minute Madness” talks. If you’re considering coming along to the session, and you meet any of the following criteria, please add your name to wiki!
- you’ve done something cool with your OPAC
- you’d like to do something cool with your OPAC
- you’d like a soapbox to rant about how much your OPAC sucks
- you’d just like an opportunity to rant about something
- you’re in need of a new soapbox
- you’ve got a box of soap
- you’re in need of a box of soap
- you’re intending to steal all of the soap from your hotel room
- you’d like to steal all of the soap from your hotel room, but you need to a box to put it all in
Remember — if you don’t volunteer, then we’ll need to unleash the JISC Press Gang 😉
Hopefully we’ll then be able to use the topics raised by the lightning talks to help shape the rest of the session.
“Why you can’t find a library book in your search engine”
It’s good to see the ongoing OCLC debacle is starting to be picked up by the mainstream press in the UK — The Guardian newspaper has a large feature in their technology supplement today: “Why you can’t find a library book in your search engine“.
Google Book Search Data API
The new Google Book Search Data API has some really cool features and I’m wondering how much of it I can shoehorn into the OPAC?
Our students increasingly expect the OPAC search box to be searching the full-text of our book stock — i.e. they type in several words that it would be useful to borrow a book about. Searching just the bog-standard MARC metadata, you’ll be lucky to get much back… and perhaps then, only if we’ve got the full table of contents in the the MARC record.
So, for example, if I do a keyword search for “english media coverage of immigrants and social exclusion” on our OPAC, I’ll find nothing. However, if I run the same query through the Google API and then filter the results (using the ISBN) to just items we hold in the library, I get 6 hits from the first 40 results that Google sends me:
- European societies fusion or fission?
- Criminal and social justice
- Human geography of the UK : an introduction
- Preserving privilege California politics, propositions, and people of color
- Black youth, racism and the state : the politics of ideology and policy
- Television : the critical view
(I’d probably find more if I also used thingISBN or xISBN to match on associated ISBNs)
I’m not going to claim that those 6 are the most relevant books we hold in the library for that particular search (I’m not sure if I’d find anything of use in the “California politics” book)… but that’s only because I have no idea what the most relevant books are and, no matter how closely I scrutinise our MARC records, I probably never will 😉 So, short of quizzing a Subject Librarian, some of those books might be a worth a quick browse …which I could do virtually with the Embedded Viewer API:
GBS_insertPreviewButtonPopup(‘ISBN:0415198437’);
I guess the big question is “how many API searches will Google let me do every day?”
Green eco-friendly catalogue PCs
Warning — long blog post ahead!
I’ve been promising to post something about our new catalogue PCs …but first, a bit of background:
Like most large(ish) academic libraries, we’ve got dedicated catalogues PCs… lots of them… on every floor! From memory, we had at least 35 of them before the start of the refurbishment. We tended to use PCs that were no longer suitable for staff and they’d often be 5 or 6 years old. Unless staff remembered to turn them off every evening, chances are they’d get left on 24/7.
After a quick Google search, it looks like the average PC & monitor uses around 2.5 pence (UK) per hour (probably more now that electricity costs have risen in the last 12 months). So, if left on 24/7, then it would use 60 pence per day, £4.20 per week, or around £218 per year. Multiply that up by the total number of PCs (35) and we might have been paying around £7,600 per year! :-S
When I saw the plans for the refurbished floors, the first thing I noted was that there was an increased number of catalogue PCs on each floor (bringing to grand total to 45). Again, if left on 24/7, that could cost us nearly £10,000 per year.
Anyway, a couple of things coincided this summer. Firstly, the University (which has been busy improving recycling, etc) was crowned the “Most Improved University” in the annual People & Planet’s Green League table (more info here). Secondly, at the Poster Promenade event in June, I spotted something interesting on one of the stands…

On the left-hand side of that photo is a small black box with a cool blue LED — a Viglen MPC-L mini PC. It ships with Xubuntu Linux, 256MB of memory and a 80GB hard drive, and has all the usual connections that you’d see on a PC (6xUSB, VGA, audio, and network). There’s no fan inside, and the metal case acts as a large heatsink for the low spec’d CPU.
Our IT Dept had evaluated them, but the non-standard operating system and the relatively poor performance had put them off. However, they looked ideal for catalogue PCs and, according to the Viglen web site, they only use £1 of electricity per year!
A quick hunt around on the Viglen web site also threw up the fact that they can be purchased with a VESA mount, so the PC can be attached to the back of a flat screen monitor — potentially a huge space saver.
Due to the limited time available, I didn’t fancy trying to figure out how to run Xubuntu as a PAC and instead I installed XP and configured it in the same way as our other catalogue PCs (using Public Web Browser as the Windows shell). The mini PC is *just* about powerful enough to run a web browser smoothly. We normally use McAfee antivirus on University PCs, but that killed the mini PC (it uses far too much CPU and too much memory), so I went with a freebie antivirus option instead.
The mini PCs weren’t too difficult to image. After finally managing to get Norton Ghost to run off a USB drive, it took about 20 minutes to image each mini PC.
So, enough talk, let’s get to the good bit with some pictures!
First of all, you’ll need a TFT monitor with 4 VESA mounting holes on the back:

The VESA mounting cage for the mini PC looks like this:

You can see the mini PC connections on these two photos:


And here you can get a feel for the size (that’s a 17″ TFT monitor behind it):


The mini PC would have no problems fitting into a 5.25″ drive bay on a standard PC:


Here’s the mini PC inside its cage:


Next up, you screw the cage onto the back of the monitor:

Shame they don’t bundle a short VGA lead with the PC!:


Then slip the mini PC into its cage and hook up the VGA cable:


The whole thing is secured using a padlock, which traps all the cables (no more stolen mice!):

From above, you can see just how small the mini PC is:


Setting them up took a little bit of time, as tidying up the various cables so that they’re hidden behind the TFT is a bit tricky:


And, voila — 6 new eco-friendly catalogue PCs and not an ugly PC base unit in sight!

I set the mini PCs up to drop the monitor into standby after 15 minutes, so hopefully we’re going to save a few thousand pounds in electricity this year and maybe we’ll manage to stay in the top 10 in next years’ Green League table 🙂
—-
[edit] I forgot to mention that the mini PC is powered using a 12 volt laptop style power adaptor.
Visual virtual shelf browsing
The Zoomii web site seems to be getting a lot of attention at the moment, so I got wondering how easy/difficult it would be do to a virtual bookshelf in the OPAC…

It’s definitely a “crappy prototype” at the moment, and the trickiest thing turned out to be getting the iframe to jump to the middle (where, hopefully, the book you’re currently browsing is shown). Anyway, you can see it in action on our OPAC.
I suspect the whole thing would work much better in Flash and it would look really cool if it used a Mac “dock” style effect. I wonder if I can persuade Iman to conjure up some Flash? 😉
Google Graphs
We’ve had loan data on the OPAC for a couple of years now, although it’s only previously been visible to staff IP addresses. Anyway, a couple of months ago, I revamped it using Google Graphs and I’ve finally gotten around to adding a stats link that anyone can peruse — you should be able to find it in the “useful links” section at the foot of the full bib page on our OPAC.
As an example, here are the stats for the 2006 edition of Giddens’ “Sociology“…
decorative tag cloud
It’s not often that I’d consider adding pure “eye candy” to the OPAC, but I couldn’t decide what would be the best way of making this tag cloud functional. So, I made an executive decision and decided it shouldn’t be functional 😀
If you run a keyword search on our OPAC, at the foot of the page you should see a keyword cloud (it might take a few seconds to appear). The cloud is generated from previous keyword searches used on our OPAC. Here’s the one for “library“…

For multi-keyword searches, an electronic coin is tossed and you either get a cloud of the union or the intersection of your keywords. The former uses previous searches that contain any of the keywords, and the later is only those that contain all of them (if that makes sense!)
As it’s not functional, the cloud is just a decorative window into the hive mind of our users.
I’m interested to hear what you think — should the cloud be functional, or does it work as just “eye candy”?