It’s high time I started blogging again, so let’s start off with something that my colleagues in the library have been talking about at recent conferences — the link between the usage of library services and the final academic grades achieved by students.
As a bit of background to this, it’s probably worth mentioning that we’ve had an ongoing project (since 2006?) in the library looking at non and low-usage of library resources. That project has helped identify the long term trends in book borrowing, e-resource usage and library visits by the students at Huddersfield. Plus, we’ve used that information to help identify specific courses and cohorts of students who probably aren’t using the library as much as they should be, as well as when is the most effective time during a course to do refresher training.
Towards the back end of last year, we worked with the Student Records Team to build up a profile of library usage by the previous 2 years worth of graduates. For each graduate, we compared their final degree grade with their last 3 years of library usage data — specifically:
- Items loaned — how many things did they borrow from the library?
- MetaLib/AthensDA logins — how often did they access e-resources?
- Entry stats — how many times did they venture in to the library?
Now, I’ll be the first to admit that these are basic & crude measures…
- A student might borrow many items, but maybe he’s just working his way through our DVD collection for fun.
- A login to MetaLib doesn’t tell you what they looked at or how long they used our e-resources.
- Students might (and do) come into the library for purely social reasons.
- Using the library is just one part of the overall academic experience.
…but they are rough indicators, useful for a quick initial check to see if there is a correlation. Plus, we know from the non & low-usage project that there are still many students who (for many reasons) don’t use the library much.
So, let’s churn the data! 🙂
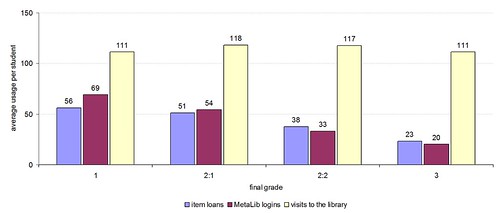
Here’s the average usage by the 3,400 or so undergraduate degree students who graduated with an honour in the 2007/8 academic year:
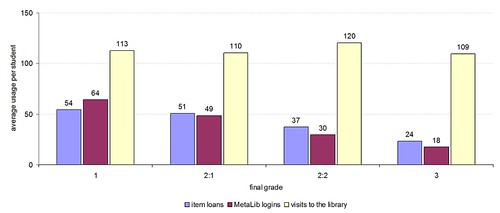
In terms of visits to the library, there’s no overall correlation — the average number of visits per student ranges from 109 to 120 — although we do seem some correlation at the level of individual courses. What does this tell us (if anything)? I’d say it’s evidence that the library is for everyone, regardless of their ability and academic prowess.
We do see a correlation with stock usage and e-resource usage. Those who achieved a first (1) on average borrowed twice as many items as those who got a third (3) and logged into MetaLib/AthensDA to access e-resources 3.5 times as much. The correlation is fairly linear across the grades, although there’s a noticable jump up in e-resource usage (when compared to stock borrowing) in those who gained a first.
Now the data for the 3,200 or students from the following academic year, 2008/9:
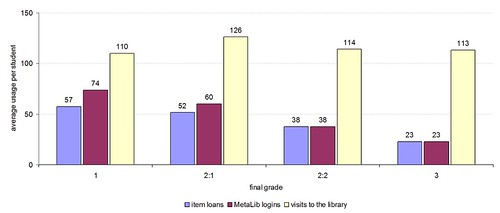
As before, no particular correlation with visits to the library, but a noticeable correlation with stock & e-resource usage. Again we see that jump in e-resource usage for those who got the highest grade.
Note too that the average usage has increased. We’ve not changed the way we measure logins or item circulation, so this is a real year-on-year growth. (Side note: as we make the move from MetaLib to Summon, the concept of an “e-resource login” will change dramatically, so we won’t be able to accurately compare year-on-year in future)
Finally, here’s both years of graduates usage combined onto a single graph:
I’m curious about that jump in e-resource usage. Does it mean, to gain the best marks, students need to be looking online for the best journal articles, rather than relying on the printed page? If that is the case, will Summon have a measurably positive impact on improving grades (it certainly makes it a lot easier to find relevant articles quickly)?
Going forward, we’ve still got a lot of work to do drilling down into the data — analysing it by individual courses, looking deeper into the books that were borrowed and the e-resources that were accessed, etc. We’re also need to prove that all this has a stastical relevance. Not only that, but how can we use that knowledge and insight to improve the services which the library offers — it’d be foolish to say “borrow more books and you’ll get better grades”, but maybe we can continue to help guide students to the most relevant materials for their students.
It’s all exciting stuff and, believe me, the University of Huddersfield Library is a great environment to work in… I just wish there were more hours in the day! 🙂