Despite a widespread network failure that seemed to affect quite a few universities, I finally managed to pick up all of the #cilip2 tweets from today’s event: http://www.daveyp.com/files/stuff/cilip2.html

Whenever I get a spare half-an-hour, I’ll do some analysis of the tweets. If anyone want a tab separated version of the data, you can grab it from here.
Tag: visualisations
3 Million
Aaron’s cool Wordle visualisations prompted me to have a look at our ever growing log of OPAC keyword searches (see this blog post from 2006). We’ve been collecting the keyword searches for just over 2.5 years and, sometime within the last 7 days, the 3 millionth entry was logged.
Not that I ever need an excuse to play around with Perl and ImageMagick, but hitting the 3 million mark seemed like a good time to create a couple of images…


The only real difference between the two is the transparency/opacity of the words. In both, the word size reflects the number of times it has been used in a search and the words are arranged semi-randomly, with “a”s near the top and “z”s near the bottom.
If I get some spare time, it’ll be interesting to see if there are any trends in the data. For example, do events in the news have any impact on what students search for?
The data is currently doing a couple of things on our OPAC…
1) Word cloud on the front page, which is mostly eye candy to fill a bit of blank space
2) Keyword combination suggestions — for example, search for “gothic” and you should see some suggestions such as “literature”, “revival” and “architecture”. These aren’t suggestions based on our holdings or from our librarians, but are the most commonly used words from multi keyword searches that included the term “gothic”.
..and, just for fun, here’s the data as a Wordle:


HotStuff 2.0
After killing off Hot Stuff due to a server upgrade, I find that I’m kinda missing it!
So, I’ve decided to have a second stab at the problem and this time the code is much cleaner and faster. In particular, I’m using Bloglines to handle fetching all of the feeds and then grabbing the new posts via the Bloglines API.
It’s too early for the code to start spotting new keywords and topics yet, so it’ll be early in the new year before it launches fully. In the meantime, feel free to check that your favourite library/librarian blogs are included in the list of sites I’m pulling content from: http://www.bloglines.com/public/liblogs.
Please post a comment with the URL of any blogs you’d like including!
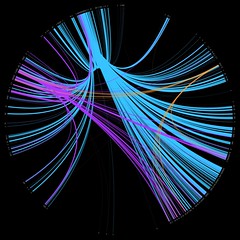
I’m hoping the make the new code a little more visual, so expect to see things like these…
[edit] HotStuff 2.0 is gradually appearing here: http://www.daveyp.com/hotstuff/
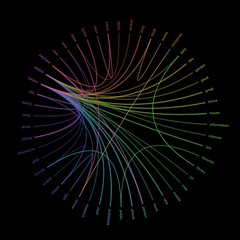
Dewey friend wheel
I’ve been meaning to have a stab at creating something similar to a friend wheel, but using library data, for a while now. Here’s a prototype which uses our “people who borrowed this, also borrowed…” data to try find strong borrowing relationships…
I picked three random Dewey numbers and hacked together a quick PerlMagick script to draw the wheel:
- 169 – Logic -> Analogy (orange)
- 822 – English & Old English literatures -> Drama (purple)
- 941 – General history of Europe -> British Isles (light blue)
The thickness and brightness of the line indicates the strength of the relationship between the two classifications. For example, for people who borrowed items from 941, we also see heavy borrowing in the 260’s (Christian social theology), 270’s (Christian church history), and the 320’s (Political science).
The next step will be to churn through all of the thousand Dewey numbers and draw a relationship wheel for our entire book stock. I’ve left my work PC on to crunch through the raw data overnight, so hopefully I’ll be able to post the image tomorrow.
Psycho collage
Following on from the book covers arranged by hue/lightness, I’ve been playing around with the 1000 Frames of Hitchcock thumbnails.
Here’s the result of 15 minutes of coding and 2 hours of rendering using a single frame from the famous shower scene in Psycho…

To see the individual frames, you really need to view the full sized image (9526 x 5475 pixels).
The code works by sampling a pixel and then randomly selecting a frame that has a similar hue and lightness value. As before, a little bit of randomess (position, rotation and size) is thrown in to make it visually more interesting.
{kind=link}
Dewey Blobs
I’ve been fascinated by data visualisation for a year or two now, and I’ve recently been chatting to my good friend Iman about doing something with our circulation data. In particular, something that will be visually interesting to look at, whilst also giving you a feel for the data.
I’ve tried a few different things, but the Dewey Blobs are currently my favourite…

(items borrowed on 23rd June)
The transactions are placed on a 32×32 grid based on their Dewey classification (000-999). Each transaction is shown as a semi-transparent circle with two attributes:
1) colour — based on the School the student making the transaction studies in
2) size — based on the popularity of the book (the larger the circle, the more times it’s been borrowed before)
Where many students from the same school borrow from the same Dewey classification on the same day, the colour is reinforced. If the borrowing is from multiple schools, then the colours begin to blend to create new hues.
For example, on this day the vast majority of transactions in the 300s were by Human & Health students (green)…

…but a couple of days later, the borrowing in the 300s is more complex, with students from several schools appearing (Business students are red and Music & Humanities students are blue)…

You can browse through a few of the blobs on Flickr.
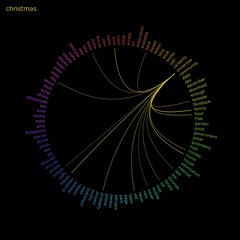
“Spin, spin, spin the Wheel of Justice…”
Kudos if you automatically sang to yourself “…see how fast the bastard turns” 😉
If you’ve no idea what I’m on about, then YouTube is your friend.
Anyway, I got to playing around with the OPAC keyword cloud data and ImageMagick and came up with this (reload that web page to get a new image)…








I was struggling to remember how to find the points on the circumference of a circle until I remembered that one of the chapters in the original ZX Spectrum manual covered the topic.
The word in the middle is chosen at random from the top 200 most popular keywords used on our OPAC and the surrounding words at those most commonly used with that word.