After killing off Hot Stuff due to a server upgrade, I find that I’m kinda missing it!
So, I’ve decided to have a second stab at the problem and this time the code is much cleaner and faster. In particular, I’m using Bloglines to handle fetching all of the feeds and then grabbing the new posts via the Bloglines API.
It’s too early for the code to start spotting new keywords and topics yet, so it’ll be early in the new year before it launches fully. In the meantime, feel free to check that your favourite library/librarian blogs are included in the list of sites I’m pulling content from: http://www.bloglines.com/public/liblogs.
Please post a comment with the URL of any blogs you’d like including!
I’m hoping the make the new code a little more visual, so expect to see things like these…
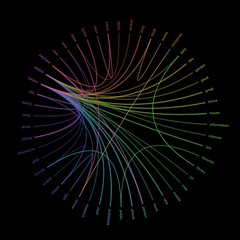
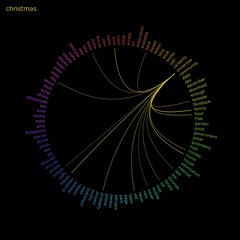
[edit] HotStuff 2.0 is gradually appearing here: http://www.daveyp.com/hotstuff/
Tag: imagemagick
Dewey friend wheel
I’ve been meaning to have a stab at creating something similar to a friend wheel, but using library data, for a while now. Here’s a prototype which uses our “people who borrowed this, also borrowed…” data to try find strong borrowing relationships…
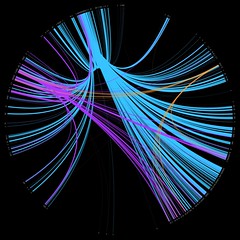
I picked three random Dewey numbers and hacked together a quick PerlMagick script to draw the wheel:
- 169 – Logic -> Analogy (orange)
- 822 – English & Old English literatures -> Drama (purple)
- 941 – General history of Europe -> British Isles (light blue)
The thickness and brightness of the line indicates the strength of the relationship between the two classifications. For example, for people who borrowed items from 941, we also see heavy borrowing in the 260’s (Christian social theology), 270’s (Christian church history), and the 320’s (Political science).
The next step will be to churn through all of the thousand Dewey numbers and draw a relationship wheel for our entire book stock. I’ve left my work PC on to crunch through the raw data overnight, so hopefully I’ll be able to post the image tomorrow.
Our books, arranged by Hue and Lightness
Sunday afternoons were made for doing this kind of thing…

(click here for the biggest version)
Several thousand of our books, arranged vertically by hue and horizontally by lightness. The value was calculated by finding the average colour of the book cover and then converting that to the relevant HSL value. There’s a little bit of randomness thrown in too, in terms of rotation and position. The image was created using Perl and ImageMagick.
If nothing else, it shows that we have more red and blue books than green or pink ones!
“Spin, spin, spin the Wheel of Justice…”
Kudos if you automatically sang to yourself “…see how fast the bastard turns” 😉
If you’ve no idea what I’m on about, then YouTube is your friend.
Anyway, I got to playing around with the OPAC keyword cloud data and ImageMagick and came up with this (reload that web page to get a new image)…








I was struggling to remember how to find the points on the circumference of a circle until I remembered that one of the chapters in the original ZX Spectrum manual covered the topic.
The word in the middle is chosen at random from the top 200 most popular keywords used on our OPAC and the surrounding words at those most commonly used with that word.
“North by Northwest” squished
After reading Brendan Dawes’ “Analog In, Digital Out“, I’ve revisited the colours of “North by Northwest” (see earlier blog post).
Rather than squish every frame to a single horizontal line, this time each frame is squished vertically — see if you can spot the “crop duster” sequence:
( full sized version on Flickr )
More “In their own words”
Here’s a few more…
Michael Stephens:

Helene Blowers:

David Lee King:

Meredith’s book:

Librarians — in their own words
I’ve spent the last couple of days being inspired by Brendan Dawes‘ book “Analog In, Digital Out“, and playing around with ImageMagick and PerlMagick.
This evening, I felt like doing something for Kathryn Greenhill to commiserate with her for not winning the “Best Librarian/Library Blog” Edublog awards, so here’s what you get if you take ImageMagick, 30 minutes of furious Perl coding, a little bit of random font rotation, a suitable JPEG source image, and the RSS feed from Kathryn’s blog…

I thought Jessamyn West‘s photo might also make for a cool textual mashup too…

In other news, Michael Stephens has gone a little dotty…

The Colours of North by Northwest
Colours, and the moods they evoke, play an important role in Hitchcock’s films.
With that in mind, I got ImageMagick to figure out the average colour of each of the 1000 frames for “North by Northwest” — you can see the results here.
To put the average colours into context, here they are annotated with a selection of scenes…

Getting the average colour of a given image got me wondering if it might be possible to do the same with the book cover scans on the OPAC. You could then virtually arrange and group books by their cover colours, in the same way that Huddersfield Public Library physically did last year:

(image courtesy of Iman’s photostream)