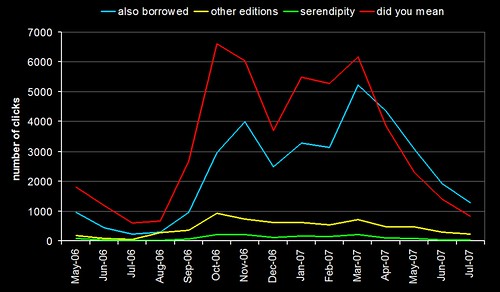
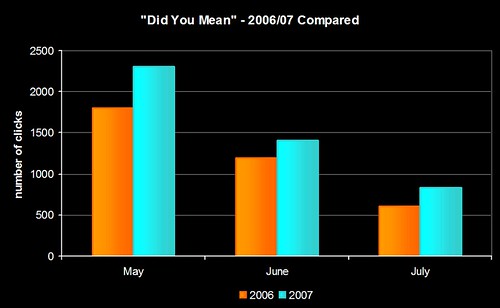
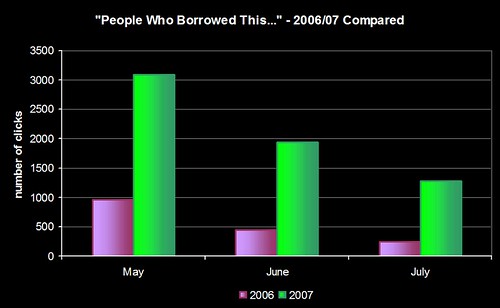
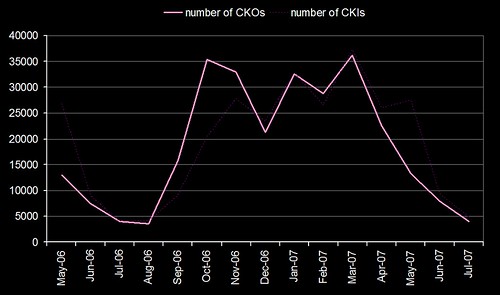
Quite a few of the conversations I’ve had this year at conferences and exhibitions have been about making data work harder (it’s also one of the themes in the JISC “Towards Implementation of Library 2.0 and the E-framework” study). We’ve had circ driven borrowing suggestions on our OPAC since 2005 (were we the first library to do this?) and, more recently, we’ve used our log of keyword searches to generate keyword combination suggestions.
However, I feel like this is really just the tip of the iceberg — I’m sure we can make our data work even harder for both us (as a library) and our users. I think the last two times I’ve spoken to Ken Chad, we’ve talked about a Utopian vision of the future where libraries share and aggregate usage data 😀
There’s been a timely discussion on the NGC4Lib mailing list about data and borrower privacy. In some ways, privacy is a red herring — data about a specific individual is really only of value to that individual, whereas aggregated data (where trends become apparent and individual whims disappear) becomes useful to everyone. As Edward Corrado points out, there are ways of ensuring patron privacy whilst still allowing data mining to occur.
Anyway, the NGC4Lib posts spurred me on into finishing off some code primarily designed for our new Student Portal — course specific new book list RSS feeds.
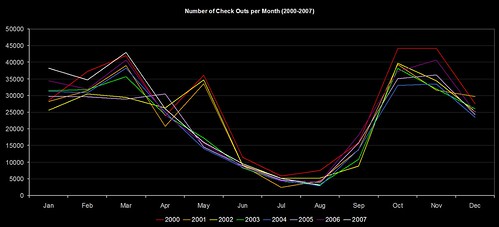
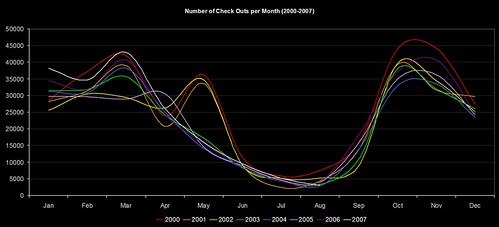
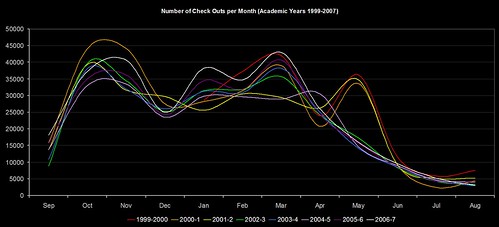
The way we used to do new books was torturous… I’ve thankfully blanked most of it out of my memory now, but it involved fund codes, book budgets, Word marcos, Excel and Borland Reportsmith. The way we’re trying it now is to mine our circulation data to find out what students on each course actually borrow, and use that to narrow down the Dewey ranges that will be of most interest to them.
The “big win” is that our Subject Librarians haven’t had to waste time providing me with lists of ranges for each course (and with 100 or so courses per School, that might takes weeks). I guess the $64,000 question is would they have provided me with the same Dewey ranges as the data mining did?
The code is “beta”, but looks to be generating good results — you can find all of the feeds in this directory: https://library.hud.ac.uk/data/rss/courses/
If you’d like some quick examples, then try these:
- Entrepreneurship MSc (course details)
- Management by Action Learning MA (course details)
- Youth and Community Work BA(Hons) (course details)
- Performing Arts (Performance) FdA (course details)
- Early Primary Education BA(Hons) (course details)
- Logistics and Supply Chain Management BSc(Hons) (course details)
- Fashion Design (Top-up) BA(Hons) (course details)
- Product Design BA/BSc(Hons) (course details)
Is your data working hard enough for you and your users? If not, why not?