If you look at the overall keyword cloud for HotStuff 2.0, you can see librar* bloggers like to talk about libraries, books, reading, books and libraries.
When some things are more popular than others, this gives rise to Tim Spalding’s “Harry Potter Effect” — everyone’s got the HP books on their shelves, so, if you’re not careful, they end up becoming the top recommendations/suggestions for almost any type of book.
In our case, in many of the keyword clouds, “library” and “book” keep on coming out as the largest words. Whilst this is an accurate reflection of what the blogs are talking about, it does hide some of the more interesting and relevant keywords.
In honour of Mr Spalding, and at the risk of getting sued silly by Mrs Rowling, I’ve added a bit of JavaScript to toggle between a full version of the cloud (“incrementum!”) and one that can sometimes bring out more interesting/relevant keywords (“redactum!”).*
As an example, the full keyword cloud for presentation has “library” as the largest word…

…click on “redactum!” and you get a cloud with some more interesting words such as “audiences” and “interaction”…

* apologies for the cod Latin!
Tag: clouds
what do bibliobloggers talk about?
As one final “hurrah” from the Hot Stuff service, I thought it would be fun to put all of the data into Wordle. Every day, for the last 2 years or so, my code has saved away the top 100 words from all of the new blog posts from around 500 librarian blogs…

http://wordle.net/gallery/wrdl/109981/biblioblogosphere
…so, from all of this painstaking research we can clearly see that librarian bloggers love to talk about books! 😉
decorative tag cloud
It’s not often that I’d consider adding pure “eye candy” to the OPAC, but I couldn’t decide what would be the best way of making this tag cloud functional. So, I made an executive decision and decided it shouldn’t be functional 😀
If you run a keyword search on our OPAC, at the foot of the page you should see a keyword cloud (it might take a few seconds to appear). The cloud is generated from previous keyword searches used on our OPAC. Here’s the one for “library“…

For multi-keyword searches, an electronic coin is tossed and you either get a cloud of the union or the intersection of your keywords. The former uses previous searches that contain any of the keywords, and the later is only those that contain all of them (if that makes sense!)
As it’s not functional, the cloud is just a decorative window into the hive mind of our users.
I’m interested to hear what you think — should the cloud be functional, or does it work as just “eye candy”?
Tweet Clouds
I have a confession to make — I grew bored of Twitter after a couple of days.
However, I felt obliged to keep on Twittering something… anything… so I hooked our OPAC into the feed instead. Every 5 minutes, a bit of code checks to see what the most popular keyword(s) used on our OPAC has been recently and, if it’s different to the last run, it fires it off to Twitter. I was so lazy, I didn’t even bother filtering out stopwords.
The result is an eclectic mix of words that encapsulate our student’s usage of the library catalogue — little snapshots of what was important to a bunch of students (or perhaps one particular determined student). Topics meander semi-randomly, occasionally repeating at unusual intervals.
Sometimes, there’s not a single popular keyword, but several. Sometimes the multiple words make sense, other times they create weird phrases…
- british genetics music
- angina attachment theatre
- education picasso sex
- rape skills study
Anyway, a few days ago I spotted Tweet Clouds and decided to see what it made of my feed…

http://www.tweetclouds.com/user_pages/daveyp.html
…and here’s a cloud I made back in December 2006…

I must admit, I feel kinda guilty that I ate up 23 minutes of CPU time on the Tweet Cloud site :-S
OPAC keyword cloud
This is crying out to be done like the visual word map in AquaBrowser, but here’s a browseable tag cloud based on data from nearly 2 million keyword searches on our OPAC.


The code looks for other keywords that were entered as part of the same search (e.g. “ethics of nursing care”) to draw out the most commonly used words. For example, the most common keyword used with “performance” is “management”. The size of the word in the cloud is determined by how often it appears with the search keyword.

I’ve not removed keywords that generated zero search results, so the cloud for “acrobat” includes “abode”. (I’ve now removed zero result searches)
I’ll have to have a play to see if there’s a way of incorporating the cloud into the OPAC — for example, if you used a vague/general keyword such as “health“, then maybe the OPAC could suggest more specific searches for “health care”, “mental health” or “health promotion”?
Library bloggers… whatcha talking ’bout now?
This is a variation of the previous cloud which attempts to show which words have been used more frequently in the last couple of days compared to previous days.
I’ve added a lot of the more common words to the stop word list (e.g. “librar*” and “google”) to try and allow some of the less frequently used words to gain importance.
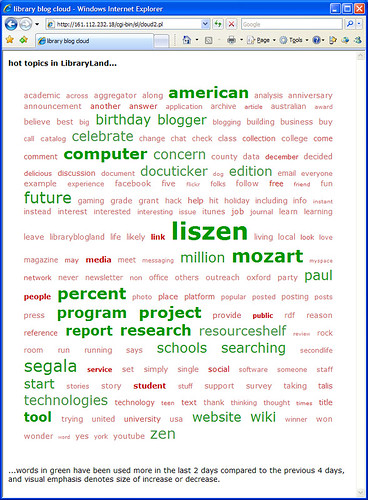
So, why is Mozart back in vogue? Several bloggers have recently posted about NMA Online (inc. Peter Scott’s Library Blog & ResourceShelf).
If a word is used several times in a post (e.g. “segala” and “liszen”) then that can make the word appear “hotter” than it perhaps should be, and some posts are appearing more than once (e.g. those from ResourceShelf) — I’ll try and fix that.
You can click on any of the words in the cloud to see links to relevant blog posts.
http://161.112.232.18/cgi-bin/sl/cloud2.pl
I’ll continue to tweak the code, so it might change over the next few days…
Library bloggers… whatcha talking ’bout?
Following on from the Second Life RSS hack, I’ve stolen borrowed an idea from Andy Powell…
To try and improve the hack, I’ve written my own RSS feed aggregator and it’s been busy sucking in around 90 library & librarian’s blogs. Then, by analysing the blog post titles and text, I’m able to produce a cloud of the most commonly used words from the last 7 days worth of posts…

…and “YouTube” isn’t one of them! 😉
The code is fairly primitive (you might spot that “del” and “icio” appear in there), but it does ignore most of the common stop words and collapses plurals in singulars.
The aggregator will continue to pull in updated RSS feeds and I’ll carry on adding other relevant blog feeds to the melting pot, so keep checking the following URL to see what’s hot in LibraryLand!
http://161.112.232.18/cgi-bin/sl/cloud.pl