Those who went to either Richard Wallis’ API session or my OPAC session at the UKSG 2009 Conference will have heard about Richard‘s Open Source Juice Project.
The project, which was launched at Code4Lib 2009, is designed to allow developers to create OPAC extensions (or, if you prefer, “bells and whistles”) that, in theory, should be product independent. This is such a genius idea!
Part of the problem with the stuff we’ve developed at Huddersfield is that we had to put an infrastructure in place around the OPAC in order to allow us to do the tweaking — an extra web server, MySQL databases, etc. It works well for us, but it’s not an easily transferable model. I’m always more than happy to share the “how we did it” but, more often than not, the actual code is too reliant on that back end infrastructure.
I need to do a bit more testing, but I’m hoping to have a HIP 3 “metadef” ready soon. The job of the metadef is to define whereabouts on the OPAC page things like the ISBN, author and title appear, and therefore will be different for every OPAC product. However, once you have a suitable metadef for your OPAC, you can start using the Juice extensions to add extra functionality — I had a quick play around last night just to prove that Juice will work with HIP 3…
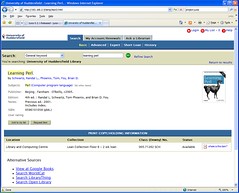
I’m not sure if this is in Richard’s plans for Juice, but it would be handy to extend the metadef to include other OPAC specific information — e.g. given an ISBN or some keywords, how do you construct a URL to trigger a search on that OPAC. That’d be really useful for embedding recommendations, etc.
2 thoughts on “Squeezing Juice into the OPAC”
Comments are closed.
Thanks for your kind words, and the heads-ups in your #uksg09 presentations.
Great that you found it easy to integrate in to HIP 3. I know I said that was the idea, but you can’t beat people trying as confirmation.
My plans for The Juice Project? – whatever the community needs and wants. The Metadef concept will hopefully foster some Juice community norms as what to expect as information for extensions to feed upon. ISBN/ISSN, Author, and Title are all obvious, but also only a start. I can see already that your fertile mind is getting to work on the possibilities that I hope to see surfacing on the project site: http://juice-project.googlecode.com
I would just briefly note that my Umlaut software approaches the same problem space as Juice. Umlaut is both a bit more complicated (the actual business logic runs on server, not javascript; js can still insert the output into your OPAC or other though), and in my opinion a lot more powerful. But yeah, more complicated too. 🙂
Through Umlaut, I am currently including in my catalog:
Google Books fulltext, search, and limited preview
Amazon search and limited preview
OpenLibrary fulltext
HathiLibrary fulltext and limited preview
Links to Ulrichs; Worldcat Identities; (coming soon) Journal Citation Reports
Entered from the link resolver end, with article-level metadata, Umlaut also provides ISI and Scopus “cited by” and other links (coming soon). And some other stuff.
Umlaut’s definitely a heavier-weight piece of software, more of a commitment. But it does cover the same basic use scenario as Juice, plus a lot more.
You could theoretically use Umlaut _without_ a link resolver to just provide title-level services like Juice does.