I’ve been meaning to have a play around with Solr, which is…
an open source enterprise search server based on the Lucene Java search library, with XML/HTTP and JSON APIs, hit highlighting, faceted search, caching, replication, and a web administration interface
It’s mostly the “faceted” part I’m interested in and, after a couple of hours of messing around, I’ve got a basic OPAC search interface up and running with around 10,000 records pulled in from our catalogue.
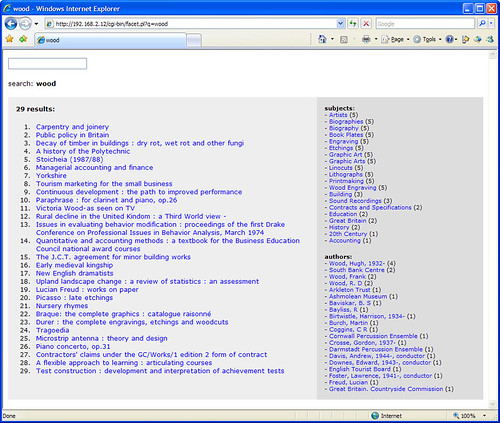
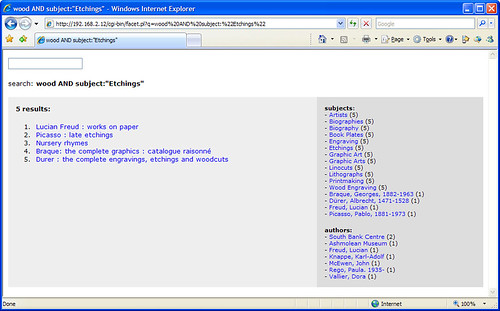
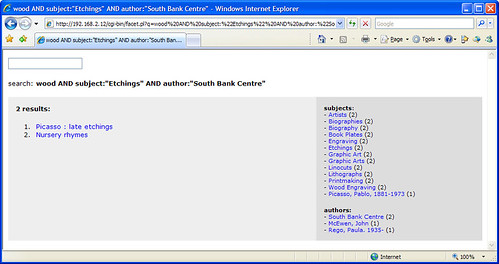
It looks like Solr automatically handles word stems, as searches for “score”, “scores”, and “scoring” find the same results. The results are also relevancy ranked, although I need to find a way to fine tune the default ranking algorithm.
All in all, I’m very impressed with what Solr can do and how quickly it handles searches.
Magic! Does SOLR include a MARC import, or did you have to massage the data in some way before-hand?
I don’t think there’s a MARC import, so I’ve just been parsing the XML output of our OPAC to grab a selection of bibliographic records.
The next step will be to play around with some of the Perl MARC modules to load the Solr database with all of our records (~350,000) and also generate more facets (e.g. item locations and collections, item types, etc).
Hi
I am impressed by the innovative ideas and solutions that have appeared here.
My question is from the perspective of the acquisitions department.
I was wondering if there was a simple way to automatically check the holdings of our horizon system (for example a list of isbns in excel, or a text document) and identify what items were already in the collection, or on order.
Also, have you ever tried making selections lists for staff available on HIP (configured for staff only)–to make use of the ability to link reviews and images for selection librarians?
Thanks
Rick
Just in case anyone is surfing by and wants to see the “work in progress”, try:
http://161.112.232.18/modperl/facet6.pl?q=medicine