Just a quick plug to say that there are still spaces available at the “Open Source: Free Speech, Free Beer and Free Kittens!” event at Hudderfield on Friday 26th June. Full details and a link to the booking form are available on the CILIP University College and Research Group web site.
Speakers at the event include:
– Ken Chad (Ken Chad Consulting)
– Nick Dimant and Jonathan Field (PTFS Europe)
– Nicolas Morin (BibLibre)
– Richard Wallis (Talis)
…although I don’t think there’ll be any free beer or kittens on offer to delegates, there will be a free lunch which is kindly being sponsored by PTFS Europe 🙂

Tag: opensource
Wow!
Kudos to everyone at the University of Prince Edward Island, Canada — in under 30 days, they’ve migrated from their legacy ILS to the Open Source Evergreen system!
One quote on Mark’s blog really jumped out at me:
This is a “skunkworks” planning process: as we progress we figure out how stuff will work and then we make it so. If we can’t make it so, we move back the appropriate number of steps until we have something that works and gives us a reasonable path to a better outcome. Much different than the normal process – the big advantage is we get used to solving problems and making accommodation, rather than striving for perfection at every turn. In this Web 2.0 world this is the way to grow. The disadvantage is that we could create configurations that will need to be changed down the road and could lead to some additional work/headaches down the road. We hope not, but working in this mode always creates that risk.
(via Lorcan Dempsey)
Solr + 2 hours = faceted OPAC
I’ve been meaning to have a play around with Solr, which is…
an open source enterprise search server based on the Lucene Java search library, with XML/HTTP and JSON APIs, hit highlighting, faceted search, caching, replication, and a web administration interface
It’s mostly the “faceted” part I’m interested in and, after a couple of hours of messing around, I’ve got a basic OPAC search interface up and running with around 10,000 records pulled in from our catalogue.
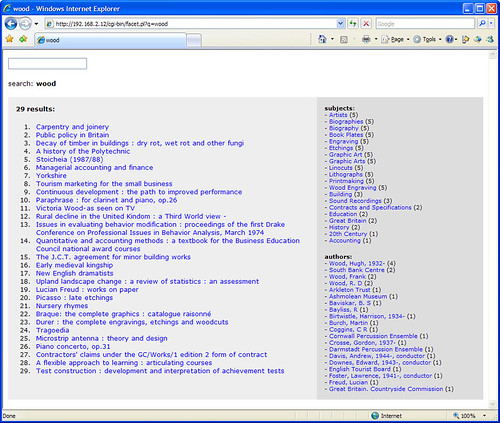
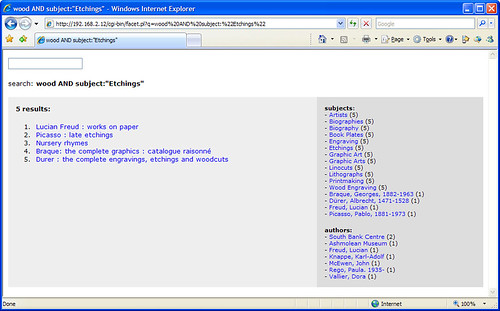
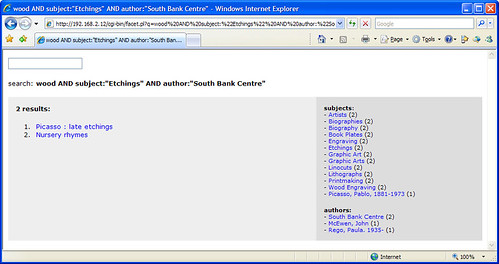
It looks like Solr automatically handles word stems, as searches for “score”, “scores”, and “scoring” find the same results. The results are also relevancy ranked, although I need to find a way to fine tune the default ranking algorithm.
All in all, I’m very impressed with what Solr can do and how quickly it handles searches.