Here’s the next batch of results — this time lots of pretty graphs 😉
The shorthand descriptions for the features are as follows:
stealth OPAC — embedding the OPAC in other applications and getting the OPAC to where the user is
did you mean — spelling suggestions for search keywords
enriched — third party book cover scans, table of contents, trusted reviews, etc
RSS feeds — new book lists, RSS feeds of searches, search alerts, etc
facets — faceted browsing of results
also borrowed — “people who borrowed this also borrowed…” suggestions based on circulation data
user tagging — allowing the user to apply their own keywords (tags) to items in the OPAC
user comments — allowing the user to add their own reviews and comments to items in the OPAC
user learning — an “intelligent” OPAC that makes personalised suggestions based on what the user does
user ratings — allowing the user to add their own ratings or scores to items in the OPAC
1) Importance of Features and the Number of Implementations
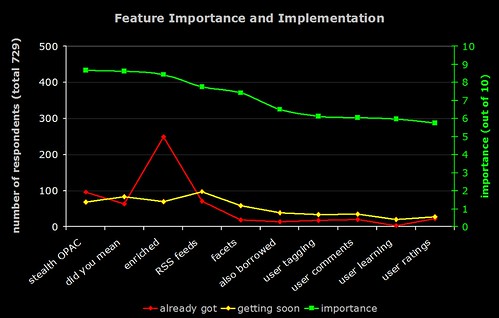
The green line (right hand axis) is the average perceived importance of the 10 OPAC features. The red line is number of respondents who have already implemented the feature, and the yellow line is the number who are planning to implement it soon.
2) Importance of Features and Predicted Number of Implementations
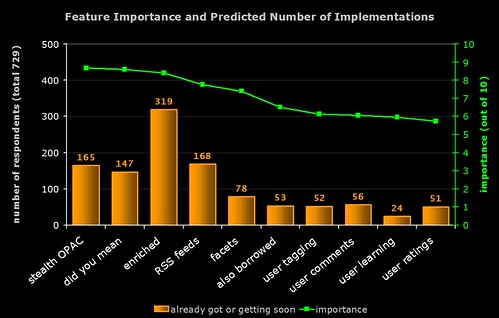
The green line (right hand axis) is the average perceived importance of the 10 OPAC features. The orange bar is number of respondents who have already implemented the feature or who are planning to implement it soon (i.e. the result of combining the red and yellow lines from the previous graph).
Note the high number of implementations of “enriched content”. In general, features with lower perceived importance are less likely to have been (or are about to be) implemented.
3) Rate of Increase of Feature Implementation
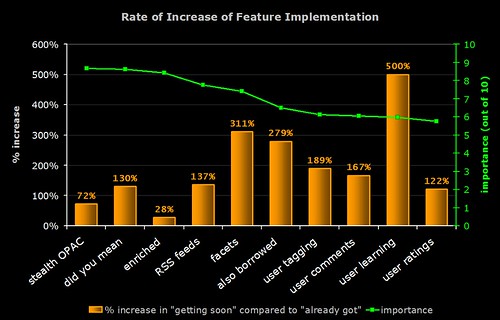
Time for some crystal ball gazing!
The green line (right hand axis) is the average perceived importance of the 10 OPAC features. The orange bar indicates the rate of increase in the implementation of the feature (calculated by dividing the number of people who are planning to implement it by the number of people who already have and expressing the result as a percentage).
For example, 249 respondents already have enriched content and 70 are planning to get it soon:
70 / 249 x 100 = 28.1%
Note that many of the features that (on average) have lower perceived importance are actually the ones whose rate of implementation is highest.
The graph indicates that "learning OPACs" (e.g. OPACs that give the user personalised suggestions and learn from what they do) are potentially the "next big thing"!
4) Feature Importance
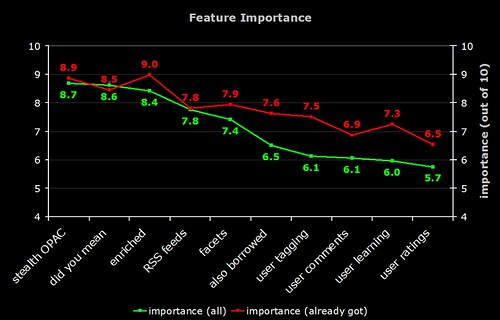
The green line is the average perceived importance of the 10 OPAC features. The red line is the perceived importance from those respondents who have actually implemented that feature.
Note that the difference in the perceived importance of the more "2.0" features (tagging, comments, etc). Does this mean those who have implemented these features are reaping the benefits?
5) Feature Importance
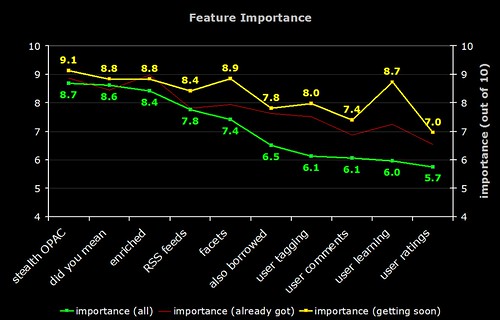
The green line is the average perceived importance of the 10 OPAC features. The faint red line is the perceived importance from those respondents who have actually implemented that feature. The yellow line is the perceived importance from those respondents who are planning to implement that feature soon.
Note that the difference in the perceived importance of the more "2.0" features (tagging, comments, etc). The "getting soon" respondents certainly have high expectations!
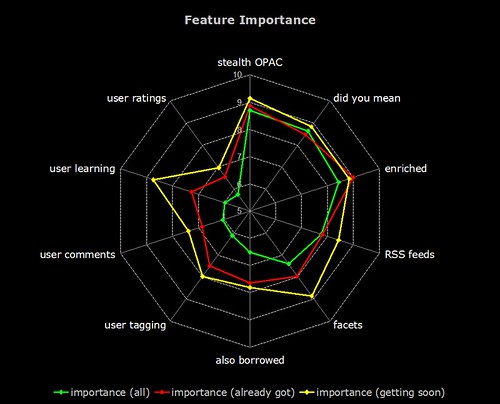
And now, the same data on a radar graph (for those who prefer this format)…
6) Feature Implementation (UK)
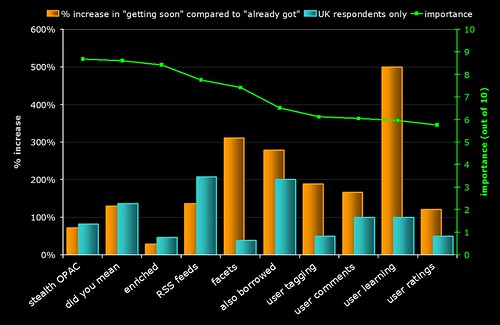
The same graph as (3) but with a blue bar showing the rate of implementation in the UK. Why is faceted browsing so low on the agenda for UK libraries? Are US libraries more aware of this feature due to the high publicity surrounding North Carolina’s OPAC?
Month: April 2007
OPAC Survey results – part 1
A few hours earlier than planned, but the informal OPAC Survey has now closed. Many thanks to everyone who responded — all 729 of you! 🙂
Here’s how the responses break down by geographical region:
After a few days, I added a question that allowed respondents to identify what type of library they worked for — 233 people answered:
Discounting regions and library types where there were 5 or less responses, here’s how the responses broke down for the first 3 sections of the survey…
1) OPAC Happiness
On a scale of 1 to 10 (where 1 is extremely unhappy and 10 is extremely happy), how happy are you with your OPAC?
2) Cutting Edge or Yesterday’s News?
One criticism of OPACs is that they rarely have cutting edge features (or perhaps even basic features) that our users expect from modern web sites. On a scale of 1 to 10, how well do you think your OPAC meets the needs and expectations of your users?
If “2007” represents a cutting edge OPAC with all the features both you and your users would expect, how far in the past do you feel your current OPAC is?
Have you ever suffered from “OPAC envy” when looking at someone else’s OPAC?
3) Child’s play?
On a scale of 1 to 10 (where 10 is extremely easy), how easy do you find your OPAC is to use?
On a scale of 1 to 10 (where 10 is extremely easy), how easy do you think one of your average users finds your OPAC is to use?
On a scale of 1 to 10 (where 10 is extremely important), how important do you think it is that an OPAC is easy and intuitive to use?
Do you run any face-to-face training or induction/introduction courses on “how to use” the OPAC with your users?
…more results to come tomorrow morning!
More Solr fun
Darn, I should have known I was following in a great man’s footsteps…
http://www.code4lib.org/2007/durfee
Anyway, a couple more hours of coding has resulted in this…
http://161.112.232.18/modperl/facet6.pl?q=medicine
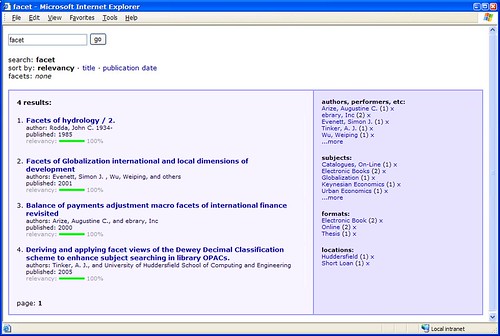
Hopefully NCSU won’t be setting their lawyers on me (copying is the most sincere form of flattery!), but the prototype has certainly borrowed one or two ideas from their wonderful OPAC.
It’s still a way off being a full OPAC replacement and I need to shrink the book covers down to a more sensible size, but I’m quite chuffed with what I’ve been able to achieve in just a few hours of coding.
Arrghhhhh – Change!
I’m sure Stephen Abram posted his “Change — Arrghhhhh!” article with all of the best intentions in the world, but unfortunately it’s not gone down well with some of the customers…
I assure you, most of us handle change quite well and if none of us wanted major change we wouldn’t be upset about the decision to trash 8.0. In fact, we have asked, begged and demanded change for years and we finally thought we were about to get some. Instead that long awaited “change” has once again been flushed down the toilet.
I was reminded of a stern grownup telling a child that he must take his cod liver oil, because it’s good for him. And I might, if I thought the New Improved Cod Liver Oil had distinct advantages over the old cod liver oil I’ve been taking for years. Problem is, I’m not convinced.
…an incredibly insulting commentary
I also think the article on change has to rate as one of the most offensive and tasteless exercises in corporate public relations ever done.
I must admit that when I read the article, my initial reaction was “what on earth was Stephen thinking when he wrote it?”. Anyway, with a quick shrug of the shoulders, I went back to doing some more coding on the Solr OPAC and the subsequent release of endorphins made me feel much happier! 🙂
I’d definitely be interested to know what some of the Unicorn sites thought of the article.
Solr + 2 hours = faceted OPAC
I’ve been meaning to have a play around with Solr, which is…
an open source enterprise search server based on the Lucene Java search library, with XML/HTTP and JSON APIs, hit highlighting, faceted search, caching, replication, and a web administration interface
It’s mostly the “faceted” part I’m interested in and, after a couple of hours of messing around, I’ve got a basic OPAC search interface up and running with around 10,000 records pulled in from our catalogue.
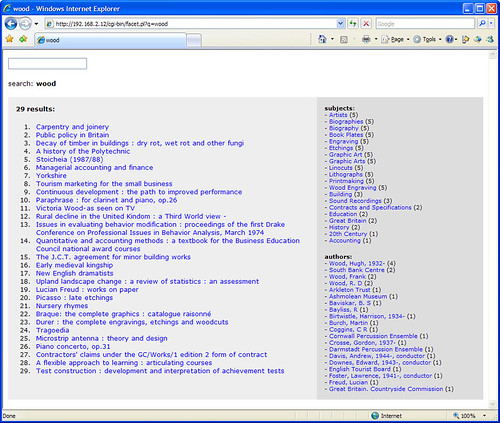
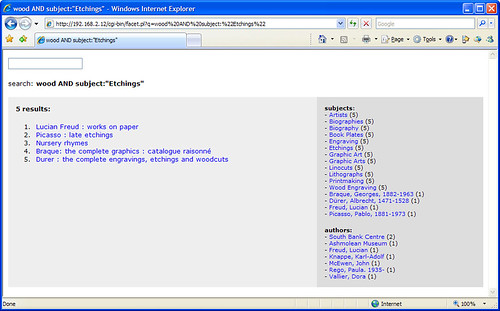
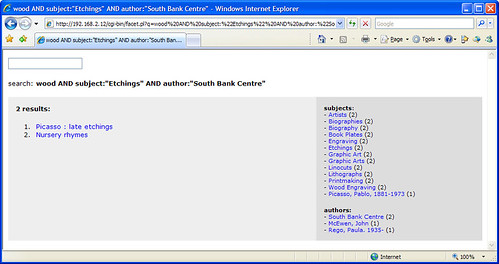
It looks like Solr automatically handles word stems, as searches for “score”, “scores”, and “scoring” find the same results. The results are also relevancy ranked, although I need to find a way to fine tune the default ranking algorithm.
All in all, I’m very impressed with what Solr can do and how quickly it handles searches.
Eeeek – my cloud has spam!
Apologies to anyone who’s picking up the “hot stuff” tag cloud feed of library/librarian weblogs — unfortunately one of the blog feeds that it aggregates has gone down with a nasty case of spam…

Rest assured that the Monty Python Vikings are currently rampaging their way through the blog feed database and masticating all of that lovely spam…
[youtube http://www.youtube.com/watch?v=ODshB09FQ8w]
“Spam spam spam spam. Lovely spam! Wonderful spam! Spam spa-a-a-a-a-am spam spa-a-a-a-a-am spam. Lovely spam! Lovely spam! Lovely spam! Lovely spam! Lovely spam! Spam spam spam spam!”
SirsiDynix Rome Sweepstake #1 – EDIFACT
Will SirsiDynix Rome support the EDIFACT standard from day 1? The US office says “no” and “probably not”, whilst the UK office says “yes”.
For UK customers, EDIFACT is pretty much an essential requirement for running a library. In fact, I suspect most libraries outside of the US require it.
So, will the first release of Rome have EDIFACT or won’t it? As the US will be doing the development, I suspect the answer might be “no”, but I’m sure I’ll shortly receive another telephone call from the UK office to say “yes” (if only to even up the scores at two all).
SirsiDynix to build Rome OPAC on Evergreen
Finally some proof that the new management at SirsiDynix are listening to their customers! I really shouldn’t post this until SirsiDynix make the official announcement on Thursday, but I just have to spill the beans because I’m so excited about the news…
Since the announcement of Rome, many Dynix and Horizon sites have been discussing a move to open source systems (such as Koha and Evergreen) and it looks like the top brass at SirsiDynix have realised that “if you can’t beat them, join them” — on Thursday they’ll be announcing a partnership with the people at Georgia Public Library Service who develop the Evergreen system.
How did I find out about this? Well, a couple of years ago I was given access to the Dynix development website and I regularly check it to see what the company has in the software pipeline. Imagine my surprise when I spotted a link titled “Evergreen Partnership OPAC” this morning — what could I do but click to see what is was!

I honestly thought that SD staff might have put it on there as some kind of joke, but a quick phone call to the press office at Huntsville confirmed the news and also that the formal announcement would come before the end of the week. They did ask me to swear that I wouldn’t leak the news, but I had my fingers crossed at the time so it doesn’t count!!! 😀
This is really great news as the Evergreen OPAC has a host of features not currently available in most ILS vendor OPAC products (including facets and lots of cool AJAX stuff).