I like sneaking in new OPAC bits when no-one’s looking and then waiting for people to discover them 🙂
Before Christmas, I was chatting to Kathryn Greenhill in Second Life about OPAC-y (or should it be “OPACeous?”) things, and I turned a vile of green when I discovered that she’s got user ratings on their OPAC at Murdoch University.
I should point out that’s “green” as in “envy” rather than as in “driving the porcelain bus“! Having said that, I like to think there might be at least a couple of ultra-conservative librarians out there somewhere who do get nauseous whenever they see Web/Library 2.0 stuff creeping into that nasty online card catalogue… just like Maggie might do in “Little Britain”:

Anyway, half an hour of frenetic mod_perl and MySQL activity later and we’ve now got something similar on our OPAC:

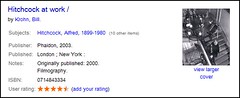
I’d like to add the facility for user comments/reviews too, but for the moment I’m happy just take a few baby steps with user ratings.
Category: Library Stuff
OPAC search cloud and failed searches
Seeing as I’ve got my head in the clouds at the moment, here’s one showing the most popular keyword search words used on our OPAC during the last 6 months…

www.daveyp.com/files/stuff/opacsearches.html
To be honest, there aren’t too many surprises in there — students studying business & law and the health sciences are the heaviest users of the library.
Unlike Yahoo, not a single person has done a search for “Britney” on our OPAC in the last 6 months …and “yes”, you would get a relevant hit if you did 😉
I’ve also separated out words that appear in failed keyword searches (i.e. they produced no hits) and removed those which did appear in other successful searches — this gives a list of keywords that probably don’t match anything on the catalogue:
- newspapermen (96)
- socail (90)
- buisness (84)
- brantingham (74)
- renew (74)
- metalib (73)
- reserach (72)
- mortor (67)
- vehclos (66)
- gieber (63)
- thoery (63)
- writting (62)
- psycology (59)
- contempory (58)
- donky (51)
- facism (47)
- reserch (46)
- reasearch (39)
- ans (38)
- hypodermic (38)
- ielts (38)
- televison (38)
- estimation (37)
- priciples (36)
- superficial (36)
- immanual (35)
- infomation (34)
- ligament (34)
- tuberclosis (34)
- centuary (33)
- resourse (33)
- topshop (33)
- treetment (33)
- devlopment (32)
- petherick (32)
- proffesional (32)
- quantitive (32)
- stamps (32)
- theorys (32)
- enviromental (31)
- pschology (31)
- statistic (31)
- syringe (31)
- hanbook (30)
- simnet (30)
- stratergy (30)
- intoduction (29)
- pestel (29)
- physio (29)
- pratice (29)
The words in bold are valid spellings (according to Microsoft Word) and the figure in brackets is the number of separate searches that contained the word.
Compared to the cloud, this is much more interesting…
1) many of them are simple typos — another good reason to add a spellchecker to your OPAC if you haven’t got one!
2) the fifth most common word is “renew” — are our users trying to renew their books by typing the word into the OPAC, or are they expecting the OPAC to work like a search engine and return something like “How to renew your books” as the first result?
3) the sixth most common word is “metalib” — it looks like a lot of people are trying to find help on using MetaLib in the OPAC… maybe we should create a dummy catalogue record that contains 856 links to MetaLib and our Electronic Resources Wiki?
4) “mortor” is an oddity in the list… but the entry for “pestel” near the end makes me wonder if people were searching for “mortar and pestle”?
Outside of the top 50, there are some other interesting failed keywords (with links to Wikipedia or other sites when relevant):
Library bloggers… whatcha talking ’bout now?
This is a variation of the previous cloud which attempts to show which words have been used more frequently in the last couple of days compared to previous days.
I’ve added a lot of the more common words to the stop word list (e.g. “librar*” and “google”) to try and allow some of the less frequently used words to gain importance.
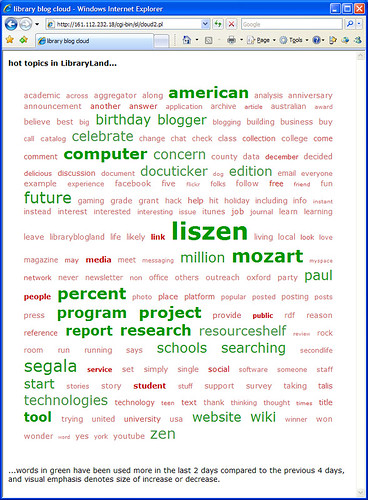
So, why is Mozart back in vogue? Several bloggers have recently posted about NMA Online (inc. Peter Scott’s Library Blog & ResourceShelf).
If a word is used several times in a post (e.g. “segala” and “liszen”) then that can make the word appear “hotter” than it perhaps should be, and some posts are appearing more than once (e.g. those from ResourceShelf) — I’ll try and fix that.
You can click on any of the words in the cloud to see links to relevant blog posts.
http://161.112.232.18/cgi-bin/sl/cloud2.pl
I’ll continue to tweak the code, so it might change over the next few days…
The tie-dyed OPAC ball
This Second Life (SL) hack is slightly more useful and is my first attempt at integrating OPAC functionality into a SL object…

Continue reading “The tie-dyed OPAC ball”
Woot! My first Second Life hack!
In what might turn out to be the most pointless thing ever done in Second Life, I’ve successfully embeded the Library 2.0 Idea Generator into an otherwise ordinary looking pavement slab…
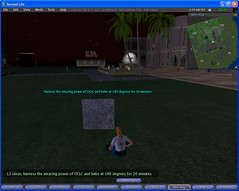
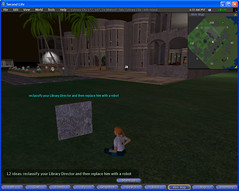
Woohoo!
in need of L2 inspiration?
Why not leverage the awesome power of the Library 2.0 Idea Generator into your own blog and paradigm shift your way into library nirvana?

If you’d like to include random ideas in your blog, just use the following code:
<script type="text/javascript"
src="/cgi-bin/l2/l24blog.pl">
</script>
If you want to also add a link back to my blog (you don’t need to if you don’t want to), just link to:
http://www.daveyp.com/blog/index.php/archives/106/
If you’d prefer to bring in a plain text idea (rather than one wrapped in JavaScript), then you can use this URL:
http://www.daveyp.com/cgi-bin/l2/l24blog.pl?plain
Have fun!
export from the OPAC to del.icio.us and LibraryThing
Yesterday, during Brian Kelly‘s opening session on Web 2.0 at the CILIP “Fly in the Web: Power to the User” event at Leeds Met, I started to think about ways of our linking library stuff into del.icio.us…
One of the things I’ve already hacked into the OPAC is the ability for a user to see their lending history — you can see a bit of it at the foot of this screen shot:

So, I decided to play around with the del.icio.us import facility to see if it was possible to export the lending history from the OPAC and then import it.
The first thing I did was to get a version of the lending history in a suitable format (see Netscape Bookmark File Format). You can see my bookmark file at this URL:
https://library.hud.ac.uk/history/5/5d/5da5fe138f7cf2…html
(I should point out that my library card gets used for a lot of testing, so I haven’t really borrowed everything on there… honest!)
If you look at the HTML source for the page, you’ll spot that I’ve included the tag “hudunilibrary” and (when available) the ISBN for each item. Each item also has a description for the last checked date & time (I’m still not sure if I should include that info?).
Once you’ve got the bookmark file, you then need to save it to your hard drive and run the import process in del.icio.us:

The only real potential problem is that del.icio.us automatically marks all imported links as “private” — so, if you want to share your lending history, then you need to manually update every link (very tedious!). Anyway, I’ve shared a few just so you can see the tag in action:
http://del.icio.us/tag/hudunilibrary
The import facility at LibraryThing is able to pick out the ISBNs in the bookmark file, so it’s also possible to transfer a subset of the lending history into there:
http://www.librarything.com/catalog_bottom.php?tag=hudunilibrary&view=daveyp
The Dynix/Horizon OPAC also has a “My List” facility, so I might see if it’s possible to hack that to output a suitable bookmark file as well.
I did mean to take a few photos at the CILIP event, but totally forget until Sheila Webber was halfway through her session on blogging — anywhere, you can find a couple of photos here. I think someone may have taken a shot of me during my workshop session, although I’m not really the most photogenic of people!
Lending paths
Whilst working on Pewbot, I wondered if you could really predict the future borrowing pattern of a user based on a specific book — in other words, if they borrow book X will they then go on to borrow book Y and then book Z?
Anyway, I’ve knocked together a basic script that will extrapolate the most likely lending path (both past and future) for a specific book.
For example, here’s the lending path for “Learning SQL: a step by step guide using Oracle”:
https://library.hud.ac.uk/perl/lendingpath/bib.pl?418925
The book in question is displayed in bold. The title directly before it (“Java: the first semester”) is the title that is most frequently borrowed prior to “Learning SQL”, and the one directly after (“Database systems: a practical approach to design…”) is the most likely to be borrowed subsequently.
In turn, I then continue to extrapolate the paths in either direction until I run out of data or a title gets duplicated.
What we end up with is a hypothetical path showing what someone is most likely to have borrowed previously, and will then go on to borrow in the future.
What’s interesting is the flow of subjects along the path — the books before are all IT books, but the future path flows into HCI, IT management, and then into corporate strategy and business titles.
If you click on a book title, then it’ll take you though to the OPAC. If you click on the “path” link, then you’ll see the lending path for that particular title.
Once you’re in the OPAC, there’s a link to the lending path at the foot of every full bib page (although the path can only be generated if there’s enough raw circulation data).
If nothing else, it proves that our students are sensible enough to borrow the Harry Potter books in the correct order! 😀
A serendipity of clouds
Insipired by the BBC Radio 1 tag cloud mentioned by Richard Wallis on the Panlibus blog, I quickly threw a couple together for the most recent search keywords used on our OPAC:

https://library.hud.ac.uk/perl/ajax5.pl

https://library.hud.ac.uk/perl/ajax5b.pl
The pages use Ajax and should automatically refresh with updated content every few seconds (assuming that someone has been searching the OPAC recently).
No points for guessing that the larger the font, the more times the word has been used in recent searches!
CODA 2006 Presentation
I can’t remember the last time I was up and out of bed before 6am, but this morning I’m giving a remote presentation about Web/Library 2.0 to the 2006 CODA Conference in Brisbane, Australia.
Given the choice, I’d much rather being doing it in person… instead of being sat here in Huddersfield where it’s pitch black outside and raining heavily!
SirsiDynix did offer to let us use their webinar software, but we’ve decided to do the presentation using Skype (for audio) and Festoon (to share my desktop).
A few years ago, I’m sure doing this would have involved someone running a copy of the presentation at the venue whilst I spoke over the telephone. However today, we’ll be doing it with free software and it won’t cost either CODA or myself a single penny/cent/dollar.
Plus, I get to do the presentation wearing a pair of jogging bottoms and an old t-shirt, and unbrushed hair! 😀