Those who went to either Richard Wallis’ API session or my OPAC session at the UKSG 2009 Conference will have heard about Richard‘s Open Source Juice Project.
The project, which was launched at Code4Lib 2009, is designed to allow developers to create OPAC extensions (or, if you prefer, “bells and whistles”) that, in theory, should be product independent. This is such a genius idea!
Part of the problem with the stuff we’ve developed at Huddersfield is that we had to put an infrastructure in place around the OPAC in order to allow us to do the tweaking — an extra web server, MySQL databases, etc. It works well for us, but it’s not an easily transferable model. I’m always more than happy to share the “how we did it” but, more often than not, the actual code is too reliant on that back end infrastructure.
I need to do a bit more testing, but I’m hoping to have a HIP 3 “metadef” ready soon. The job of the metadef is to define whereabouts on the OPAC page things like the ISBN, author and title appear, and therefore will be different for every OPAC product. However, once you have a suitable metadef for your OPAC, you can start using the Juice extensions to add extra functionality — I had a quick play around last night just to prove that Juice will work with HIP 3…
I’m not sure if this is in Richard’s plans for Juice, but it would be handy to extend the metadef to include other OPAC specific information — e.g. given an ISBN or some keywords, how do you construct a URL to trigger a search on that OPAC. That’d be really useful for embedding recommendations, etc.
Category: Library Stuff
The impact of book suggestions/recommendations?
Whilst finalising my presentation for the 2009 UKSG Conference in Torquay, I thought it would be interested to dig into the circulation data to see if there was any indication that our book recommendation/suggestion services (i.e. “people who borrowed this, also borrowed…” and “we think you might be interested in…”) have had any impact on borrowing.
Here’s a graph showing the range of stock that’s being borrowed each calendar year since 2000…
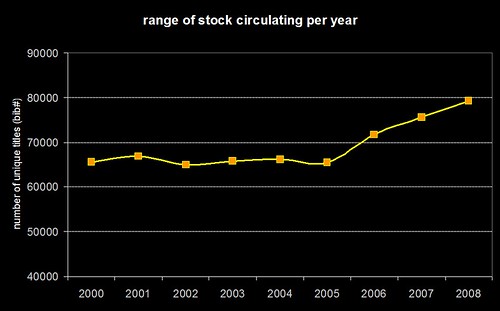
Just to be clear — the graph isn’t showing the total number of items borrowed, it’s the range of unique titles (in Horizon speak, bib numbers) that have been borrowed. If you speak SQL, then we’re talking about a “count(distinct(bib#))” type query. What I don’t have to hand is the total number of titles in stock for each year, but I’d hazard a guess that it’s been fairly constant.
You can see that from 2000 to 2005, borrowing seems to have been limited to a range of around 65,000 titles (probably driven primarily by reading lists). At the end of 2005, we introduced the “people who borrowed this, also borrowed…” suggestions and then, in early 2006, we added personalised “we think you might be interested in…” suggestions for users who’ve logged into the OPAC.
Hand on heart, I wouldn’t say that the suggestions/recommendations are wholly responsible for the sudden and continuing increase in the range of stock being borrowed, but they certainly seem to be having an impact.
Hand-in-hand with that increase, we’ve also seen a decrease in the number of times books are getting renewed (even though we’ve made renewing much easier than before, via self-issue, telephone renewals, and pre-overdue reminders). Rather than hanging onto a book and repeatedly renewing it, our students seem to be exploring our stock more widely and seeking out other titles to borrow.
So, whilst I don’t think there’s a quick any easy way of finding out what the true impact has been, I’m certainly sat here with a grin like a Cheshire cat!
Moving and Shaking
Congratulations to all the other Movers & Shakers!
Although I found out a couple of months ago that I’d made the list, I’m still really bemused by it all. Partly because it came out of the blue, but mostly because I can easily think of a dozen people who are infinitely more deserving. However, I’ll gladly try and grab my 5 minutes of fame 🙂
At the risk of doing a “Kate Winslet“, there are lots of people I’d like to thank for getting me to where I am today! Back in 2005, John Blyberg‘s innovative work at Ann Arbor gave me the confidence to start fiddling with our own OPAC. Fortunately, Dynix’s developers had created an OPAC that was fairly simple to tweak and an ILS that was easy to query, so it wasn’t an uphill struggle. (I can’t stress just how important it is that ILS vendors give their customers flexible and extensible products)
Since then, a plethora of people have continued to inspire me (in no particular order and far from complete) — Jenny Levine, Casey Durfee, Tim Spalding, Tony Hirst, Jonathan Rochkind, Helene Blowers, Casey Bisson, Kathryn Greenhill, Michael Stephens, Brian Kelly, Brendan Dawes, Richard Wallis, Phil Bradley, Stephen Abram… and, oh God, who’s the other one?!? 😉
A big “hi” to everyone who puts up with my inane waffling in the LSW chat room — you guys and girls rock! 🙂
An especially big “thank you” to my long suffering friends and colleagues at the University of Huddersfield. I’m extremely fortunate to work in a library that both innovates and inspires innovation. (Did you know Huddersfield had one of the first facetted PACs back in the 1990s? It might not be as well known as NCSUs OPAC, but Dr. Steve Pollitt‘s pioneering HIBROWSE system laid the groundwork for Endeca.)
Finally, another big “thank you” to Iman Moradi and Bryony Ramsden.
Iman’s probably the closest thing we’ve got to a “Superpatron” at Huddersfield and his boundless energy and support for the library never fails to amaze me. This year, he’s got his students playing with library data and creating visualisations — how cool is that?!
Bryony, my partner of 14 years, never seems to mind the endless hours I spend on the PC at home — for that, and many other reasons, I’m eternally grateful to her!
So, to all the unsung Movers & Shakers out there in libraries throughout the world, karma++ 🙂
QR Codes in the OPAC?
Just wondering if anyone out there is already experimenting with QR Codes in their OPAC?
We’re trying to figure out the best way of providing item location information (e.g. floor and shelfmark), so I’m interested to know if anyone has already done this.
Mash Oop North
Coming this summer…

We’re hoping to fix the date soon, but it’s likely to be on or around Tuesday July 7th at the University of Huddersfield.
If it is July 7th, then we’d be able to celebrate:
…that both events occurred on July 7th is not a coincidence 😉
(mashed potato courtesy of jslander)
OPAC Survey 2009
Almost 2 years ago, 729 of you generously took time to fill out a survey about OPACs (archived here). You can find a selection of blog posts about the results here.
I’m pleased to say that a follow-up survey is now being conducted by Bowker and I’d encourage as many of you as possible to fill it in. For every 100 responses, Bowker will donate a gift of schoolbooks to deprived children via the Oxfam Unwrapped scheme 🙂

I think in 2007 we managed to gather enough statistical evidence to say “OPACs suck” and it’ll be interesting to see how much has changed in the last couple of years! Quite a few of you were hoping to implement new features in your OPACs …did it happen? …did those features meet your expectations?
3 Million
Aaron’s cool Wordle visualisations prompted me to have a look at our ever growing log of OPAC keyword searches (see this blog post from 2006). We’ve been collecting the keyword searches for just over 2.5 years and, sometime within the last 7 days, the 3 millionth entry was logged.
Not that I ever need an excuse to play around with Perl and ImageMagick, but hitting the 3 million mark seemed like a good time to create a couple of images…


The only real difference between the two is the transparency/opacity of the words. In both, the word size reflects the number of times it has been used in a search and the words are arranged semi-randomly, with “a”s near the top and “z”s near the bottom.
If I get some spare time, it’ll be interesting to see if there are any trends in the data. For example, do events in the news have any impact on what students search for?
The data is currently doing a couple of things on our OPAC…
1) Word cloud on the front page, which is mostly eye candy to fill a bit of blank space
2) Keyword combination suggestions — for example, search for “gothic” and you should see some suggestions such as “literature”, “revival” and “architecture”. These aren’t suggestions based on our holdings or from our librarians, but are the most commonly used words from multi keyword searches that included the term “gothic”.
..and, just for fun, here’s the data as a Wordle:


ITV Unforgiven – campus shots
Following on from the last blog post, here’s some of the “on-campus” photos…

(that naughty faked “York” signage)

(Quayside, staged to look like a student cafeteria)


(The Art & Design section of the Main Library — apparently the few seconds of footage that appeared in the final programme took 3 hours to shoot!)

(St Paul’s Hall — a venue that attendees of the world famous Huddersfield Contemporary Music Festival will be familiar with)


(outside the Creative Arts Building — the foundation stone was unveiled by The Queen in 2007)

(inside the Creative Arts Building, with St Paul’s Hall in the background)


(Storthes Hall, student accommodation)
Hey up — we’re on TV!
The last episode of “Unforgiven” (IMDB) has just finished, and it featured quite a bit of footage filmed on-campus at the University of Huddersfield — mostly in the new Creative Arts Building, opposite the library…

However, if you watched the programme, you probably spotted that the TV production crew covered up the University of Huddersfield signage and replaced it with “University of York”. They even used the same font and design as York!!!
I’m not sure if there’s anyone from York reading this blog, but I’m curious to know what exactly happened. Presumably the University of York gave the production company permission to use their corporate branding? If so, why didn’t they just do the filming at York in the first place? I’m also surprised that the top brass at Huddersfield gave the production company permission to dress our University as another one — especially one that wasn’t a fictional university :-S
Anyway, if you did watch the final episode, the parts where Ruth Slater (played by Suranne Jones) followed her sister (Emily Beecham) to the university were filmed at Huddersfield in the Creative Arts Building and in the Quayside area of the Central Services Building.
Talis Podcast
I can’t remember if I was using my “posh telephone voice”, but Richard Wallis has just posted a podcast that was recorded yesterday afternoon with Patrick Murray-John.
It’s definitely worth fast-forwarding past my inane waffley bits to listen to Patrick’s comments, as he makes some great points. Using usage data for marketing purposes wasn’t something that had occurred to me, but it’s a fantastic idea!
Even though it was an informal chat, I kept feeling twinges of “job interview syndrome” — that horrible sensation you get when you’re busy talking and you realise you’ve forgotten what the actual question was :-S
For my sins, I’m going to be doing something about OPACs and usage data at the upcoming JISC Developer Happiness Days event along with Ken Chad.
p.s. Can I propose a drinking game for this podcast? The rules are you have to have a drink every time someone mentions Tony Hirst‘s name ;-D