Many thanks to those of you who’ve tested the code from yesterday! Those of you outside of the UK might want to see if this version works slightly faster for you:
hippie_spellcheck_v0.02.txt
The next thing I’ll be looking at is how to optimise the spellchecker dictionary for each library. Some of you will already have read this in the email I sent out this morning or in the comment I left previously, but I’m thinking of attacking it this way:
1) Start off with a standard word list (e.g. the 1000 most commonly used English words) to create the spellcheck dictionary for your library, as the vast majority should match something on your catalogue.
2) Add some extra code to your HIP so that all successful keyword searches get logged. Those keywords can then be added to your dictionary.
It could even be that starting with an empty dictionary might prove to be more effective (i.e. don’t bother with step 1) — just let the “network effect” of your users searching your OPAC generate the dictionary from scratch (how “2.0” is that?!)
To avoid any privacy issues, the code for capturing the successful keywords could be hosted locally on your own web server (I should be able to knock up suitable Perl and PHP scripts for you to use). Then, periodically, you’d upload your keyword list to HIPpie so that it can add the words to your spellchecker dictionary.
What about if you don’t have SirsiDynix HIP? Well, as mentioned previously, the spellchecker has been implemented as a web service (more info here), and the HIP spellchecker makes use of that web service to get a suggestion. At the moment it only returns text or XML, but I’m planning to add JSON as an option soon. Also, if you have a look at the HIP stylesheet changes, you can see the general flow of the code:
1) insert a div with an id of “hippie_spellchecker” into the HTML
2) make a call to “https://library.hud.ac.uk/hippie_perl/spellchecker2.pl” with your library ID (currently “demo”) and the search term(s) as the parameters
3) the call to “spellchecker2.pl” returns JavaScript to update the div from step 1
4) clicking on the spelling suggestion triggers the “hippie_search” JavaScript function which is responsible for creating a search URL suitable for the OPAC (which might include things like a session ID or an index to search)
None of the above 4 steps are specifically tied to the SirsiDynix HIP and should be transferable to other OPACs. I’ve put together a small sample HTML page that does nothing apart from pull in a suggestion using those 4 steps:
example001.html
If you do want to have a go with your own OPAC, please let me know — at some point I’ll need people to register their libraries so that each can have their own dictionary, and I might start limiting the number of requests that any single IP address can make using the “demo” account. Also, it would be good to build up a collection of working implementations for different OPACs.
Category: Library Stuff
HIPpie “Did you mean?” ready for testing (again!)
A thousand apologies to those of you who’ve been waiting for HIPpie to reach the testing phase — has it really been 6 months since I last posted anything?! HIPpie was/is a project that I’ll be doing in my spare time and, unfortunately, since Christmas, my spare time has been taken up with everything but working on HIPpie!
Anyway, having realised that it’s so long since I posted anything, I was shamed into making some time and I’m now at the stage where some brave HIP 3.x library can alpha test the spellchecker code. Ideally you want to be doing this on a test HIP 3.x server, unless you’re feeling particularly reckless.
The usual caveats apply — make sure you safely back up any files you edit and you promise not to hold me responsible if your server room mysteriously burns down shortly after you add the code. Also, altering your XSL stylesheets may have an impact on what support SirsiDynix will be able to give you.
To test the code, you’ll need to edit the searchinput.xsl stylesheet. Once you’ve found the file, make a safe backup before you make the changes! Open up the file and scroll down to around line 580 — you should see a <center> tag. After that tag, you need to insert (i.e. copy & paste) in the contents of this file:
hippie_spellcheck_v0.01.txt
Save the altered file and give your HIP server a minute to pick up the altered stylesheet. Now fire up a web browser and run a search for a misspelled word. If you get an error message, then double-check the changes you made to the stylesheet and, if all else fails, you can revert back to your backed up version. Touch wood, you should get a “did you mean” suggestion which looks like this:
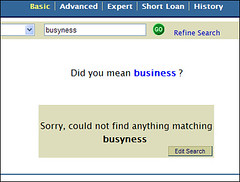
If you do test the code, please feed back!
Notes
This test version of the code is using a fairly small American dictionary of words, so you may not get appropriate suggestions for your locale.
ALA 2008
Just in case anyone’s not already spotted it, Owen Stephens is doing a fantastic job of blogging ALA 2008.
I’ve been pondering trying to organise a UK library unconference for a while now, but haven’t progressed it any further than the “pipe dream” stage. I wonder if I could persuade Kathryn Greenhill to immigrate to the UK? 😉
Anyway, if a UK library unconference/barcamp/hackfest style event is of interest to you, make sure you leave a comment on Owen’s “Mashed Libraries? Would you be interested?” thread.
Visual virtual shelf browsing
The Zoomii web site seems to be getting a lot of attention at the moment, so I got wondering how easy/difficult it would be do to a virtual bookshelf in the OPAC…

It’s definitely a “crappy prototype” at the moment, and the trickiest thing turned out to be getting the iframe to jump to the middle (where, hopefully, the book you’re currently browsing is shown). Anyway, you can see it in action on our OPAC.
I suspect the whole thing would work much better in Flash and it would look really cool if it used a Mac “dock” style effect. I wonder if I can persuade Iman to conjure up some Flash? 😉
Google Graphs
We’ve had loan data on the OPAC for a couple of years now, although it’s only previously been visible to staff IP addresses. Anyway, a couple of months ago, I revamped it using Google Graphs and I’ve finally gotten around to adding a stats link that anyone can peruse — you should be able to find it in the “useful links” section at the foot of the full bib page on our OPAC.
As an example, here are the stats for the 2006 edition of Giddens’ “Sociology“…
Stuck on a train
The joys of free wifi slightly make up for the fact that I’m stuck on a train that’s going nowhere fast — the East Coast main line is suffering long delays due to the train which was ahead of mine managing to damage and bring down the overhead power lines :-S
Today was the first meeting for the JISC Towards Implementation of Library 2.0 and the e-Framework (TILE), held at the impressive LSE Library in London.
I’m still not 100% sure what the TILE Project will manage to achieve, but it was great to spend 4 hours in a room full of people who are keen to liberate and share library data, primarily for the benefit of our users.






Wow!
Kudos to everyone at the University of Prince Edward Island, Canada — in under 30 days, they’ve migrated from their legacy ILS to the Open Source Evergreen system!
One quote on Mark’s blog really jumped out at me:
This is a “skunkworks” planning process: as we progress we figure out how stuff will work and then we make it so. If we can’t make it so, we move back the appropriate number of steps until we have something that works and gives us a reasonable path to a better outcome. Much different than the normal process – the big advantage is we get used to solving problems and making accommodation, rather than striving for perfection at every turn. In this Web 2.0 world this is the way to grow. The disadvantage is that we could create configurations that will need to be changed down the road and could lead to some additional work/headaches down the road. We hope not, but working in this mode always creates that risk.
(via Lorcan Dempsey)
Where did all the books go?
The University of Hudderfield Library is entering into the 2nd phase of a 3 year refurbishment. Last year, it was the entrance floor, and this year it’s the two subject floors above. Floor 5 is already cleared of stock, and floor 6 will be empty by the end of next week.
I couldn’t resist spending a few minutes wandering around the deserted floor 5 this afternoon. Most times of the year, it’s a vibrant and busy subject floor — today is was eiree and desolate. With the shelving and staff gone, you get a real sense of the space and size…


The floor of the former PC room is dotted with circular patches where the culmulative effect of hundreds of students on PC swivel chairs has gradually worn away the carpet. It’s like something out of a sci-fi film where people get zapped and turned into a small round pile of ash 😉

You can find the rest of the photos here.






2008 — The Year of Making Your Data Work Harder
Quite a few of the conversations I’ve had this year at conferences and exhibitions have been about making data work harder (it’s also one of the themes in the JISC “Towards Implementation of Library 2.0 and the E-framework” study). We’ve had circ driven borrowing suggestions on our OPAC since 2005 (were we the first library to do this?) and, more recently, we’ve used our log of keyword searches to generate keyword combination suggestions.
However, I feel like this is really just the tip of the iceberg — I’m sure we can make our data work even harder for both us (as a library) and our users. I think the last two times I’ve spoken to Ken Chad, we’ve talked about a Utopian vision of the future where libraries share and aggregate usage data 😀
There’s been a timely discussion on the NGC4Lib mailing list about data and borrower privacy. In some ways, privacy is a red herring — data about a specific individual is really only of value to that individual, whereas aggregated data (where trends become apparent and individual whims disappear) becomes useful to everyone. As Edward Corrado points out, there are ways of ensuring patron privacy whilst still allowing data mining to occur.
Anyway, the NGC4Lib posts spurred me on into finishing off some code primarily designed for our new Student Portal — course specific new book list RSS feeds.
The way we used to do new books was torturous… I’ve thankfully blanked most of it out of my memory now, but it involved fund codes, book budgets, Word marcos, Excel and Borland Reportsmith. The way we’re trying it now is to mine our circulation data to find out what students on each course actually borrow, and use that to narrow down the Dewey ranges that will be of most interest to them.
The “big win” is that our Subject Librarians haven’t had to waste time providing me with lists of ranges for each course (and with 100 or so courses per School, that might takes weeks). I guess the $64,000 question is would they have provided me with the same Dewey ranges as the data mining did?
The code is “beta”, but looks to be generating good results — you can find all of the feeds in this directory: https://library.hud.ac.uk/data/rss/courses/
If you’d like some quick examples, then try these:
- Entrepreneurship MSc (course details)
- Management by Action Learning MA (course details)
- Youth and Community Work BA(Hons) (course details)
- Performing Arts (Performance) FdA (course details)
- Early Primary Education BA(Hons) (course details)
- Logistics and Supply Chain Management BSc(Hons) (course details)
- Fashion Design (Top-up) BA(Hons) (course details)
- Product Design BA/BSc(Hons) (course details)
Is your data working hard enough for you and your users? If not, why not?
Sexy SirsiDynix shenanigans in sunny Southampton
(Well, it’ll be sexy in-so-far as I’m including some gratuitous nudity in my session on “RSS and Social Networking” on Thursday. Will I be stripping off and revealing all in the name of “2.0”? You’ll have to come along and find out!)
I’m currently sat in Manchester Airport, waiting for a budget flight down to Southampton, which is playing host to this year’s “Dynix Users Group/European Unicorn Users Group Joint Conference“. High on the agenda is the merging of the two user groups, and hopefully a shorter name — my personal choice is still “SirsiDynix Libraries User Group”, if only for the cool “SLUG” acronym.
As Ian has already mentioned on his blog, European Horizon users are crossing their fingers that SirsiDynix CEO Gary Rautenstrauch’s “commitment to our worldwide customer base” will result in an announcement that Horizon 7.4.2 will be made available to non-US customers. Sadly, the 7.4.1 release was a US only affair and UK sites are still tootling along (quite merrily, it has to be said) on 7.3.4.
Right — must dash, my boarding gate has just been announced! 3G card allowing, I’m hoping to blog and Flickr the conference.