Just a quick plug to say that there are still spaces available at the “Open Source: Free Speech, Free Beer and Free Kittens!” event at Hudderfield on Friday 26th June. Full details and a link to the booking form are available on the CILIP University College and Research Group web site.
Speakers at the event include:
– Ken Chad (Ken Chad Consulting)
– Nick Dimant and Jonathan Field (PTFS Europe)
– Nicolas Morin (BibLibre)
– Richard Wallis (Talis)
…although I don’t think there’ll be any free beer or kittens on offer to delegates, there will be a free lunch which is kindly being sponsored by PTFS Europe 🙂

Category: Library Stuff
Web service for the free book usage data
I’ve been meaning to get around to adding a web service front end on to the book usage data that we released in December for ages. So, better late than never, here it is!
It’s not the fastest bit of code I’ve ever written, but (if there’s enough interest) I could speed it up.
The web service can be called a couple of different ways:
1) using an ISBN
Examples:
a) https://library.hud.ac.uk/api/usagedata/isbn=0415014190 (“Language in the news”)
b) https://library.hud.ac.uk/api/usagedata/isbn=159308000X (“The Adventures of Huckleberry Finn”)
Assuming a match is located, data for 1 or more items will be returned. This will include FRBR style matching using the LibraryThing thingISBN data, as shown in the second example where we don’t have an item which exactly matches the given ISBN.
2) using an ID number
Examples:
a) https://library.hud.ac.uk/api/usagedata/id=125120 (“Language and power”)
The item ID numbers are included in the suggestion data and are the internal bibliographic ID numbers used by our library management system.
——————-
edit 1: I should also have mentioned that the XML returned is essentially the same format as described here.
edit 2: Ive now re-written the code as a mod_perl script (to make it faster when using ISBNs) and slightly altered the URL
Tracking the library angle on swine flu
For anyone who’s interested in how libraries and librarians are blogging about the swine flu outbreak, I’ve just added a dedicated RSS feed over on the HotStuff 2.0 blog: http://www.daveyp.com/hotstuff/?p=268

Transcript of the #cilip2 Twitter hastag
Despite a widespread network failure that seemed to affect quite a few universities, I finally managed to pick up all of the #cilip2 tweets from today’s event: http://www.daveyp.com/files/stuff/cilip2.html

Whenever I get a spare half-an-hour, I’ll do some analysis of the tweets. If anyone want a tab separated version of the data, you can grab it from here.
OCLC to launch web based ILS
I’m guessing it’s safe to post this now, although I’m still expecting a phone call from lawyers representing OCLC and/or The Library Journal after “accidentally” stumbling on the news before it officially broke :-S
The LJ article (written by Marshall Breeding) isn’t live at the moment, but it the annoucement has appeared on the OCLC home pages:
– OCLC announces strategy to move library management services to Web scale
– Andrew Pace: And now for something completely different
Twittering ideas
Is your library looking a little tired and shabby? Are you patrons listless and lackadaisical? Are you in need of inspiration? Have you shifted your paradigms recently? Do you believe that ideas should come at regular 15 minute intervals and always be less than 140 characters long?
I should have thought of hooking the Library 2.0 Idea Generator into Twitter a long time ago 😀
Keyword search data
We’ve been logging all keyword searches on our OPAC for nearly 3 years and now have details for over 3 million searches. Just in case the data is of any use to anyone, I’ve uploaded an aggregated XML version to our web server: https://library.hud.ac.uk/data/keyworddata/
As with the usage data, we’re putting it out there with no strings attached by using an Open Data Commons Licence.
The XML file contains a list of about 8,500 keywords. For each keyword, there’s a list of other terms that have been used with that keyword in multi-term searches. The readme file contains more information about the structure.
Books that connect users
I thought it would be interesting to trawl the data and find out which books have been borrowed by the largest number of different courses within the university. I forget what the correct Graph Theory term is, but these are the books (nodes?) that connect together (edges?) the largest number of separate groups of students (networks?). The figure in brackets is the number of different courses that have borrowed the book.
- Questionnaire design, interviewing and attitude measurement by Oppenheim (245)
- Doing your research project: a guide for first-time researchers in education and social science (3rd ed) by Bell (215)
- Real world research: a resource for social scientists and practitioner-researchers (2nd ed) by Robson (190)
- Organisational behaviour and analysis: an integrated approach by Rollinson, Broadfield & Edwards (167)
- Sociology (3rd ed) by Giddens (161)
- The reflective practitioner: how professionals think in action by Schön (152)
- Experiential learning: experience as the source of learning and development by Kolb (150)
- Strategic management: awareness and change (3rd ed) by Thompson (134)
- Strategic management: an analytical introduction (3rd ed) by Luffman (133)
- Sociology: themes and perspectives (5th ed) by Haralambos & Holborn (133)
- Educating the reflective practitioner: toward a new design for teaching and learning in the professions by Schön (131)
- The good research guide: for small-scale social research projects by Denscombe (129)
- Qualitative data analysis: an expanded sourcebook (2nd ed) by Miles & Huberman (127)
- Health promotion: foundations for practice (2nd ed) by Naidoo & Wills (125)
- Team roles at work by Belbin (124)
- Research methods in education (5th ed) by Cohen, Manion & Morrison (124)
- How to research by Blaxter, Hughes & Tight (124)
- Understanding organizations (4th ed) by Handy (123)
- Basics of qualitative research: techniques and procedures for developing grounded theory (2nd ed) by Strauss & Corbin (121)
- The study skills handbook by Cottrell (120)
- Health promotion: models and values (2nd ed) by Downie, Tannahill & Tannahill (120)
- Doing qualitative research: a practical handbook by Silverman (116)
- Marketing by Lancaster & Reynolds (116)
- Reflection: turning experience into learning by Boud, Keogh & Walker (113)
- Management (6th ed) by Stoner, Freeman & Gilbert (109)
- No sweat!: the indispensable guide to reports and dissertations by Irving & Smith (109)
- The good study guide by Northedge (106)
- Research methods for nurses and the caring professions (6th ed) by Abbott & Sapsford (106)
- Marketing by Lancaster & Reynolds (106)
- Operations and the management of change by Gilgeous (106)
Conversely, these are the books that have only ever been borrowed by students on one specific course. The figure in brackets is the number of loans.
- The meaning of everyday occupation by Hasselkus (61)
- Perspectives in human occupation: participation in life by Kramer, Hinojosa & Royeen (48)
- Introduction to podopediatrics (2nd ed) by Thomson & Volpe (42)
- Occupational therapy without borders: learning from the spirit of survivors by Algado, Pollard & Kronenberg (38)
- Transformation through occupation by Watson & Swartz (38)
- Operating department practice A-Z by Smith & Williams (31)
- Lully, lulla, thou little tiny child: for soprano solo and SATB (unaccompanied), op.25 no.2 by Leighton (31)
- Five childhood lyrics: for unaccompanied mixed voices by Rutter (31)
- Task analysis: an occupational performance approach by Watson & Llorens (30)
- Conditions in occupational therapy: effect on occupational performance (3rd ed) by Atchison & Dirette (30)
The impact of serendipity (part 2)
I promised I’d dig a bit deeper into the book data, so here goes!
We have seven academic schools in the university, so I thought it would be interesting to see how the range of titles broke down by each school. As previously noted, the borrowing patterns seem to have changed at the end of 2005/start of 2006, so here’s the percentage change for the two periods…
academic school average range of titles borrowed % change
2000-2005 2006-2008
Music, Humanities & Media 16,760 20,468 122.1%
Business 9,431 11,402 120.9%
Computing & Engineering 7,033 6,771 96.3%
Education 12,485 11,909 95.4%
Human & Health Sciences 16,427 20,274 123.4%
Applied Sciences 7,356 7,562 102.8%
Art, Design & Architecture 9,361 12,309 131.4%
So, first of all, the increase in range of titles being borrowed isn’t across the board. I knew Computing & Engineering borrowing had been in decline for a number of years, but I’m surprised to see that the same applies for Education. Applied Sciences has stayed pretty much the same, but the other 4 schools have seen sizeable increases in the range of titles being borrowed.
The Art & Design section of the library was revamped in 2005, so it could be that we’ve seen an increase in the number of students using the library and that has driven the increased borrowing since then for that school.
A few of the comments suggested that loans per borrower would be a useful metric. Unfortunately I don’t have the data for the total number of students in each school per year, so I’m using the total number of active borrowers instead…
academic school average loans per active borrower % change
2000-2005 2006-2008
Music, Humanities & Media 26.1 25.7 98.6%
Business 10.2 12.3 121.4%
Computing & Engineering 8.3 7.7 93.6%
Education 15.1 14.0 92.8%
Human & Health Sciences 15.3 18.8 122.6%
Applied Sciences 11.8 13.3 112.1%
Art, Design & Architecture 10.6 10.4 98.4%
Again a decline in Computing and Education. Art & Design and Music & Humanities have remained pretty much the same. The other 3 schools have seen an increase in the number of loans per active borrower.
One final set of data — the number of active borrowers per school…
academic school average active borrowers per school % change
2000-2005 2006-2008
Music, Humanities & Media 1,537 1,976 128.5%
Business 2,557 2,963 115.8%
Computing & Engineering 1,650 1,527 92.5%
Education 1,526 1,988 130.3%
Human & Health Sciences 3,587 4,581 127.7%
Applied Sciences 1,267 1,243 98.1%
Art, Design & Architecture 1,621 2,332 143.9%
It looks like there are a couple of things going on here…
1) In the last 3 years, the number of active borrowers (i.e. users who have borrowed at least one item) has increased. In the period 2000-2004, the total number of active student borrowers was relatively static (around 14,000) and since 2005 it’s been on the increase (with just over 17,000 in 2008).
2) Overall, there’s an increase in the average number of books borrowed per active borrower, primarily driven by the two schools with the highest number of active borrowers (Business and Human & Health). The increases in those two schools more than offsets the decreases seen in a couple of the other schools (Computing and Education).
At a time when some other UK academic libraries have reported a decrease in borrowing, both of the above are good news for our library. I’ll need to go back to the SCONUL stats to check, but I don’t think we’ve seen much of an increase in book stock in the last decade (I suspect it might actually have decreased).
So, can we actually say anything about the impact of serendipity? If we look in more depth at the average number of books borrowed per active borrower per year for all students, we get this…
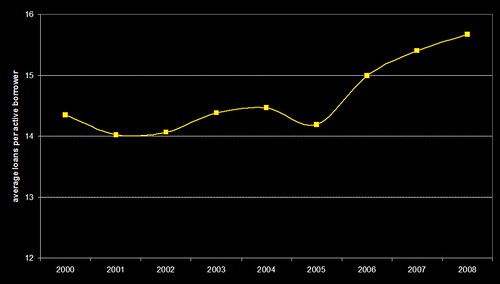
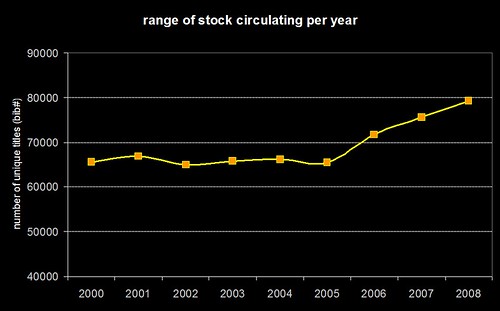
…which closely resembles the original graph from the first post showing the range of unique titles borrowed per year…
…and the number of active borrowers per year also shows a similar trend…
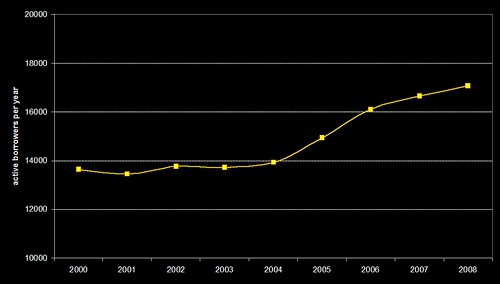
It’s obvious that there’s a driver in there somewhere which has caused the average number of loans per active borrower to increase since 2005. Hand-in-hand there’s been a similar increases in the range of stock that’s being borrowed and the number of active borrowers.
As more people use the library, one would perhaps expect the range of stock being borrowed to increase. However, would you also expect the average number of loans per borrower to increase (bearing in mind that the stock levels have probably not increased and may have actually decreased during that period)?
I’m still not entirely sure I’ve shown that adding serendipity to an OPAC increases the range of stock being borrowed (that’s probably more influenced by the number of active borrowers), but there may well be a link with the average number of books loaned to each borrower.
Now, to change the topic, here’s one final graph that I included in the UKSG presentation — it shows the number of clicks per month on the books in the OPAC’s virtual shelf browser…

…seeing as this was just an experimental feature that added a bit of “book cover eye candy” to the OPAC, I’m amazed how heavily it’s being used. Whilst fixing one of our dedicated catalogue PCs in the library on Friday, I noticed that a student was carrying out a search, then picking a relevant search result, then using the shelf browser to look at all of the nearby books. And to think I’m usually dismissive of the benefits of browsing within OPACs 😀
A library dating service
In my UKSG presentation, I briefly touched on the need for library services (perhaps the OPAC, but perhaps not) to start joining users together in the same way that sites like Facebook do.
In the same way that a “people who borrowed this, also borrowed…” service starts exposing the hidden links between items on shelves, I think we need to start finding the connections between our users.
Using circulation data, we can start to locate clusters of users who’ve borrowed the same books. In an academic environment, these may be students who are studying on the same course. However, what if we discovered that two separate courses being run in different parts of the university had a strong overlap in borrowing? Would value be gained from introducing those students to each other?
No sooner had I tweeted that I was thinking about this kind of thing, Tony Hirst sent a response…
…a library dating service, then? Heh heh 😉
I’m keen to know what your first reaction to Tony’s comment is!
What if you were a lonely researcher who wanted to find someone similar to yourself, in order to collaborate on a project? By mining the circulation data and/or OpenURL article access data, a library could find your ideal partner — someone who’d been looking at the same books and resources that you’d been using. If libraries were aggregating their usage data at a national level, that perfect partner could well be a researcher at another institution.
To test this out, I tweaked our “people who borrowed this” code to generate the links between users (rather than the books). As an aside, I’ve been trying all day to figure out what the user equivalent of “people who borrowed this, also borrowed…” is, but haven’t been able to wrap my head around the logical linguistics of it!
Data Protection obviously means that I can share that prototype with you, but it did throw up some interesting results. For my partner Bryony, her closest match was one of her colleagues who works in the same department as her — they both share similar craft related interests, so have borrowed similar books. However, what if her closest match was someone working in another department? Maybe they’d want to meet up over a coffee and swap crafty ideas.
I also tried the same for one of my colleagues, who’s a lecturer, and found that his ideal match is himself! Or rather, the closest match for his current library account (as a member of staff) was his old library account from when he was a student. In other words, since becoming a lecturer, he’s re-borrowed quite a few of the books he used as a student.
Although I can’t show you the data for individuals, we can step back a level and look at the borrowing at the course level. I’ve put together a quick and dirty prototype to play with. The prototype will pick a course at random and then show the courses that have the closest matches in terms of book borrowing — if you’re unlucky and get an empty list (i.e. no matches were found), try refreshing the page.
Taking the BSC Applied Criminology course as an example — 59.3% of the books borrowed by students on that course were also borrowed by students on the BSC Behavioural Sciences course (HB100). The other top matches all seem to be related to criminology: psychology, social work, police studies, child protection, probation work, etc. However, there also appears to be some synergy with books borrowed by midwifery, history and hospitality management students.
I’ll try and add some extra code in tomorrow to show what the most popular books are that inhabit those course intersections.