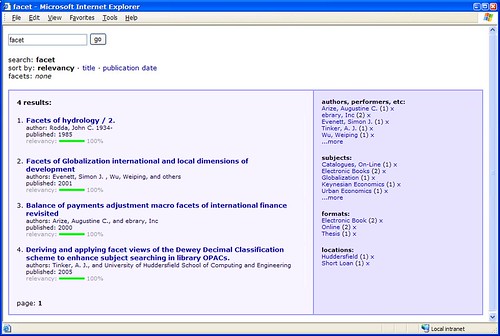
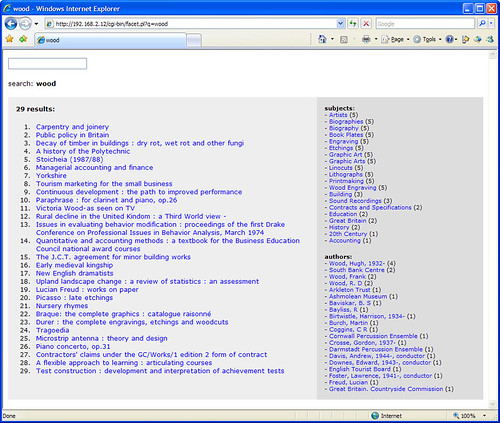
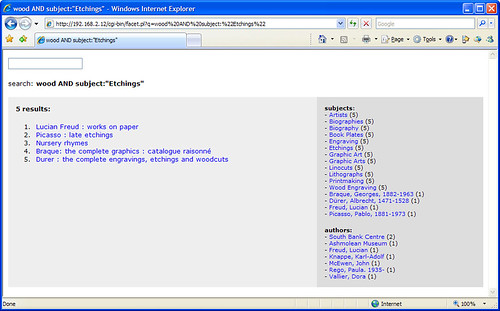
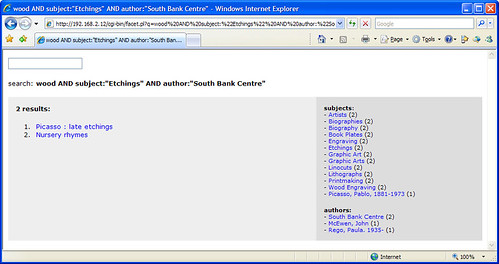
I have a confession to make — I grew bored of Twitter after a couple of days.
However, I felt obliged to keep on Twittering something… anything… so I hooked our OPAC into the feed instead. Every 5 minutes, a bit of code checks to see what the most popular keyword(s) used on our OPAC has been recently and, if it’s different to the last run, it fires it off to Twitter. I was so lazy, I didn’t even bother filtering out stopwords.
The result is an eclectic mix of words that encapsulate our student’s usage of the library catalogue — little snapshots of what was important to a bunch of students (or perhaps one particular determined student). Topics meander semi-randomly, occasionally repeating at unusual intervals.
Sometimes, there’s not a single popular keyword, but several. Sometimes the multiple words make sense, other times they create weird phrases…
- british genetics music
- angina attachment theatre
- education picasso sex
- rape skills study
Anyway, a few days ago I spotted Tweet Clouds and decided to see what it made of my feed…

http://www.tweetclouds.com/user_pages/daveyp.html
…and here’s a cloud I made back in December 2006…

I must admit, I feel kinda guilty that I ate up 23 minutes of CPU time on the Tweet Cloud site :-S